
Robert Ross
CEO, FireHydrant
Robert believes that better incident management is integral to a world where all software is reliable. He founded FireHydrant in 2018 as the tool he wished he’d had when managing incidents on call at companies like Namely and DigitalOcean.

FireHydrant to be Acquired by Freshworks
By Robert Ross
|

Signals Is Lighting Up the Future of On-Call: Eight (Yes, 8!) New Features Just Released
By Robert Ross
|
The Price Engineering of Signals
By Robert Ross
|

The New Retrospective Experience Is Now Available to All 🎉
By Robert Ross
|
The Hidden Value of Declaring Lower Severity Incidents
By Robert Ross
|
Hot Take: Don't provide incident resolution estimates
By Robert Ross
|
Press Release: FireHydrant Acquires Blameless to Further Solidify Enterprise Market Leadership
By Robert Ross
|

Semantic search with Ruby on Rails
By Robert Ross
|
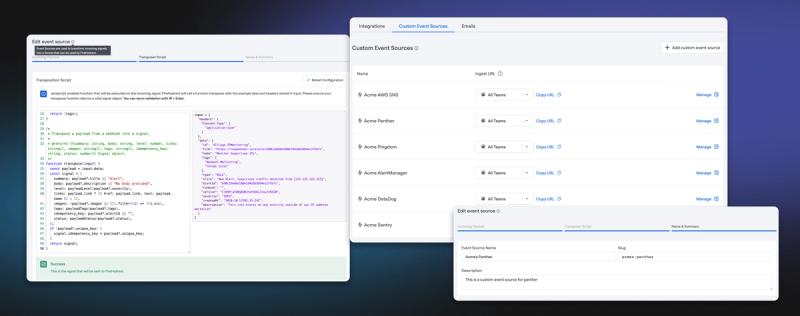
BYO Payload: Custom event sources for Signals have landed
By Robert Ross
|
Beyond the Headlines: The Unsung Art of Software Outage Management
By Robert Ross
|
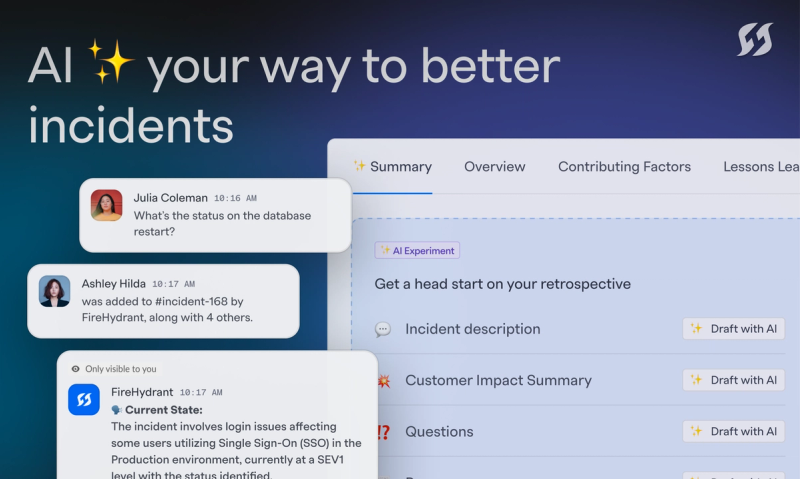
FireHydrant is now AI-powered for faster, smarter incidents
By Robert Ross
|
3 Questions to Ask When Choosing DevOps Automation Tools
By Robert Ross
|

Finally: alerting and on-call scheduling for how you actually work
By Robert Ross
|

The alert fatigue dilemma: A call for change in how we manage on-call
By Robert Ross
|
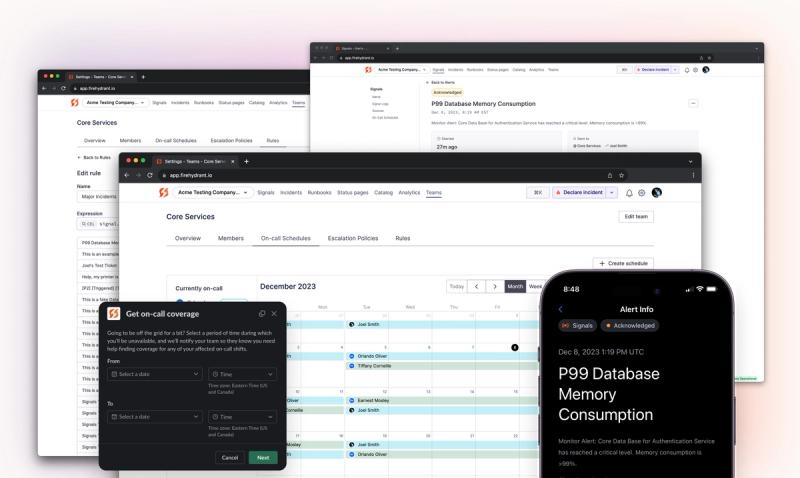
Now in beta: alerting for modern DevOps teams
By Robert Ross
|

Captain's Log: Diving into our scheduling design
By Robert Ross
|
Captain's Log: How we are leveraging CEL for Signals
By Robert Ross
|
Captain's Log: A first look at our architecture for Signals
By Robert Ross
|
The new principles of incident alerting: it's time to evolve
By Robert Ross
|

More than downtime: the cultural drain caused by poor incident management
By Robert Ross
|
More than downtime: the opportunity costs of poor incident management
By Robert Ross
|
More than downtime: the explicit costs of poor incident management
By Robert Ross
|
Exploring distributed vs centralized incident command models
By Robert Ross
|

210% ROI: unlocking the economic value of FireHydrant for incident management
By Robert Ross
|
The “people problem” of incident management
By Robert Ross
|
Assembly time is where you have the most control of an incident
By Robert Ross
|
How FireHydrant handled the SVB banking crisis
By Robert Ross
|
The hidden costs of poor incident management
By Robert Ross
|
A better way: 3 incident response areas prime for automation
By Robert Ross
|

You really like us: customer trust wins FireHydrant 3 G2 awards
By Robert Ross
|

Learn from 50,000 incidents with the first Incident Benchmark Report
By Robert Ross
|

Integrations on Rails: How we build and deploy integrations at FireHydrant
By Robert Ross
|

New reports stress the importance of strategic incident management practice
By Robert Ross
|

3 mistakes I’ve made at the beginning of an incident (and how not to make them)
By Robert Ross
|

Words matter: incident management versus incident response
By Robert Ross
|

3 ways to improve your incident management posture today
By Robert Ross
|

The not-so-obvious positive outcomes of great incident management
By Robert Ross
|

Understanding Service Level Objectives
By Robert Ross
|
Best practices for building an incident management plan and process
By Robert Ross
|

FireHydrant is now free for small teams
By Robert Ross
|

Incident severity vs priority: What’s the difference?
By Robert Ross
|

Avoid frostbite: Stop doing code freezes
By Robert Ross
|

Reliability is not an engineering metric
By Robert Ross
|

Chaos Engineering Your Incident Management Process
By Robert Ross
|

Getting Started with Site Reliability Engineering
By Robert Ross
|

We’ve raised a $23M Series B to help us get to a world where all software is reliable
By Robert Ross
|

Pragmatic Incident Response: 3 Lessons Learned from Failures
By Robert Ross
|

The MTTR that matters
By Robert Ross
|

Four things to consider when evaluating incident management platforms
By Robert Ross
|

Alert Fatigue and Your Health
By Robert Ross
|

It's Time We Throw Out the Usage of 'Postmortem'
By Robert Ross
|

New Feature: Incident Types
By Robert Ross
|

2021 is the Year of Reliability
By Robert Ross
|

The Final Episode - Episode 10 of Throughput Thursdays
By Robert Ross
|

Configuring a Runbook - Episode 9 of Throughput Thursdays
By Robert Ross
|

Breaking down the interface - Episode 8 of Throughput Thursdays
By Robert Ross
|

More New Terraform Resources - Episode 7 of Throughput Thursdays
By Robert Ross
|

Creating a Data Source - Episode 6 of Throughput Thursdays
By Robert Ross
|

Testing Our Terraform Resources - Episode 5 of Throughput Thursdays
By Robert Ross
|

Adding Two Terraform Resources - Episode 4 of Throughput Thursdays
By Robert Ross
|

Fixing Some Code Sins - Episode 3 of Throughput Thursdays
By Robert Ross
|

Build Your API First
By Robert Ross
|

Live from Cape Cod - Episode 2 of Throughput Thursdays
By Robert Ross
|

We’re Building a Terraform Provider! - Episode 1 of Throughput Thursdays
By Robert Ross
|

July Product Updates: Status Pages, Incident Redesign, and more
By Robert Ross
|
The Culture of the Codebase
By Robert Ross
|

Announcing Our Series A
By Robert Ross
|

The Old Fashioned
By Robert Ross
|

Avoid Institutionalized Incident Nonsense
By Robert Ross
|
Announcing Runbooks
By Robert Ross
|

NFS with Docker on macOS Catalina
By Robert Ross
|

Open Source can be a Silver Bullet, but your Application Might be a Werewolf
By Robert Ross
|

Dynamic Kubernetes Informers
By Robert Ross
|

Announcing our Statuspage.io Integration
By Robert Ross
|
3 Defensive Programming Techniques for Rails
By Robert Ross
|

A Gophers Guide to San Diego
By Robert Ross
|
Product Updates: July 2019
By Robert Ross
|
Announcing Flare: Make Opening Incidents Stress Free
By Robert Ross
|

So You Want To Give A Tech Talk?
By Robert Ross
|

New Features: Webhooks + Saved Searches
By Robert Ross
|
Severity Matrix Updates
By Robert Ross
|

Rails without Webpacker
By Robert Ross
|

Instrumenting Ruby on Rails with Prometheus
By Robert Ross
|

Understanding Istio Ingress
By Robert Ross
|

Developing a Ruby on Rails app with Docker Compose
By Robert Ross
|
Stay Informed with Kubernetes Informers
By Robert Ross
|

Develop a Go app with Docker Compose
By Robert Ross
|
Flexible Ruby on Rails Reader Objects
By Robert Ross
|
New Releases: SSO, Post Mortem Generator
By Robert Ross
|

How FireHydrant Creates Data in Rails
By Robert Ross
|
New Feature: Incident Status Pages
By Robert Ross
|

Announcing FireHydrant, a Tool to Manage Incidents
By Robert Ross
|