Integrations on Rails: How we build and deploy integrations at FireHydrant
This post explores how we built FireHydrant in a way that allows us to rapidly build and deploy integrations to help our product fit into responders’ workflows and not vice versa.

Implementing integrations without a mountain of technical debt can be challenging. But it doesn’t have to be all bugs, burn out, and outages when shipping integrations at a high volume. We’ve unlocked a pattern at FireHydrant to rapidly build and release integrations without swiping the technical debt credit card each time — and that gave us a fastlane to building premier integrations.
Since Day 1, when we launched with Slack, PagerDuty, and Jira integrations, we’ve understood that any product made to make managing incidents easier has to seamlessly integrate with the workflows responders are already using. Now, three years and nearly two dozen integrations into our architecture later, I’m here to report good news: it is possible to build an integration platform that effectively and efficiently scales with your customers' demands.
In this blog post, I’ll show you how, complete with data diagrams, code architecture, snippets from our codebase (with minimal modifications), and lessons learned or what we’d do differently. Let’s dig in.
FireHydrant’s integration architecture#firehydrants-integration-architecture
Our architecture can be transposed into any language and framework, but this post will use examples from our stack:
- Ruby on Rails 6
- Postgres
- Google Cloud Platform
Starting at the top, we have our organization model which stores the data about a company using FireHydrant. Nothing to write home about. And then we have our namespace: “integrations.” Let’s break down two of the models here first.
Integrations::Integration
Our integration model doesn’t belong to anything in our data model directly. It exists to solely record which integrations are available for installation in FireHydrant. The database schema looks like this:
CREATE TABLE public.integrations (
id uuid DEFAULT public.gen_random_uuid() NOT NULL,
name character varying NOT NULL,
slug character varying NOT NULL,
capabilities character varying[] DEFAULT '{}'::character varying[] NOT NULL,
favicon_url character varying,
logo_url character varying,
summary text,
description character varying DEFAULT ''::character varying
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);Note: Pay attention to the capabilities column of this table the most. That’s where the magic of our integration platform starts to come to life. More on that soon.
Integrations::Connection
Perhaps a better name for this model would be Integrations::Installation. This record is created when an organization installs an integration. In reality, this table doesn’t act as anything other than a through model minus other simple metadata.
CREATE TABLE public.integrations_connections (
id uuid DEFAULT public.gen_random_uuid() NOT NULL,
authorized_by_type character varying NOT NULL,
authorized_by_id uuid NOT NULL,
organization_id uuid NOT NULL,
account_id bigint NOT NULL,
connection_type character varying NOT NULL,
connection_id uuid NOT NULL,
integration_id uuid NOT NULL,
status public.integration_connection_status NOT NULL,
disconnected_at timestamp without time zone,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);The connection model stores who installed an integration, its status (connected or not), and most importantly, the connection record associated with the installed integration. We accomplish this in Rails with a polymorphic association.
The directory structure in our Rails application is:
app/
models/
integrations/
integration.rb
connection.rb
slack/
connection.rb
jira_cloud/
connection.rb
pager_duty/
connection.rbIntegrations::JiraCloud::Connection
One of our most popular and important integrations is with Jira Cloud (we support Jira Server, too). With this integration, you can create a ticket in Jira whenever an incident is opened in FireHydrant. When we distilled this “simple” request down, it came down to three capabilities we needed to support: listing projects, creating tickets, and syncing state.
How we register new integrations in FireHydrant#how-we-register-new-integrations-in-firehydrant
All of our integrations are defined in a file called “integrations.yml” that contain the name, slug, and most importantly, the capabilities the integration supports.
- name: Jira Cloud
slug: jira_cloud
favicon_url: "/integrations-assets/jira_cloud/favicon.png"
logo_url: "/integrations-assets/jira_cloud/logo.png"
capabilities:
- ticketing.projects
- ticketing.tickets
- ticketing.webhook_sync
- meta.connection_status_check
- auth.oauth2
- ticketing.project.configsThis YAML is parsed with a simple class that we can call via a rake task or by clicking a button in our internal admin application.
class ~Integrations::CreateAllInternal~
def self.call
parsed = ::Integrations.internal_integrations_configuration
parsed["integrations"].each do |i|
create_or_update_from_integration_config!(integration_config: i)
end
end
def self.create_from_slug(integration_slug:, configuration: nil)
configuration ||= ::Integrations.internal_integrations_configuration
integration_config = configuration["integrations"].find { |c| c["slug"] == integration_slug }
create_or_update_from_integration_config!(integration_config: integration_config)
end
def self.create_or_update_from_integration_config!(integration_config:)
integration_slug = integration_config["slug"]
integration = Integrations::Integration.find_by(slug: integration_slug)
if integration.present?
integration.assign_attributes(
name: integration_config["name"],
description: integration_config["description"],
capabilities: integration_config["capabilities"],
favicon_url: integration_config["favicon_url"].to_s,
logo_url: integration_config["logo_url"].to_s,
)
integration.save!
else
Integrations::Integration.create!(integration_config)
end
end
endOnce an integration is created or updated in our database, users are able to install it via the UI in FireHydrant.

But what now? Let’s focus on what makes our integration platform flexible: capability clients.
Integration principles#integration-principles
We’ve built our integration platform with the idea of generic abstractions for data. For example, Jira may call things “tickets” but Shortcut calls them “stories” and GitHub calls them “issues” (here’s where that functional overlap I mentioned at the top of the post comes in). You have to have a healthy discussion to come to a conclusion of what you want to call these pieces of data internally. For us, we called them Tickets and Projects, and we map data from integrations accordingly.
Creating and updating projects#creating-and-updating-projects
If integrations have capabilities, our codebase has capability clients. A capability client implements an interface for the capability it is initiated for. For example, “ticketing.projects” will require the capability client:
- Initializes with the
Integrations::JiraCloud::Connection - Implements
#projects
Our Ruby capability client for JiraCloud projects is pretty small, this is it in its entirety:
class ~Integrations::JiraCloud::ProjectsClient~
def initialize(connection)
@connection = connection
end
# Fetches all projects on Jira and assigns them to a value object to be used for
# storing in external resource objects (typically, it may have other uses).
def projects
api_client.projects.map do |project|
::Ticketing::IntegrationProject.new(project.id, project.name, project.as_json)
end
end
private
attr_reader :connection
delegate :api_client, to: :connection
end
And, because we distill down ideas into generic abstractions, we have a Ticketing::Project model that our capability client feeds records into that we care about. We synchronize projects every 15 minutes using Rufus Scheduler:
scheduler.cron "15 * * * *", job_name: "ticketing_update_projects" do
Organization.find_each do |organization|
ConnectionFinder.all_for_capability(organization, "ticketing.projects").each do |connection|
Ticketing::UpdateProjectsJob.perform_later(organization, connection)
end
end
endWe desperately wanted to avoid adding a model like “Ticketing::JiraProject” as it gets unwieldy quickly. Instead, we have a generic model under the hood that relates external data (Jira tickets) to internal data abstractions (a FireHydrant ticket).
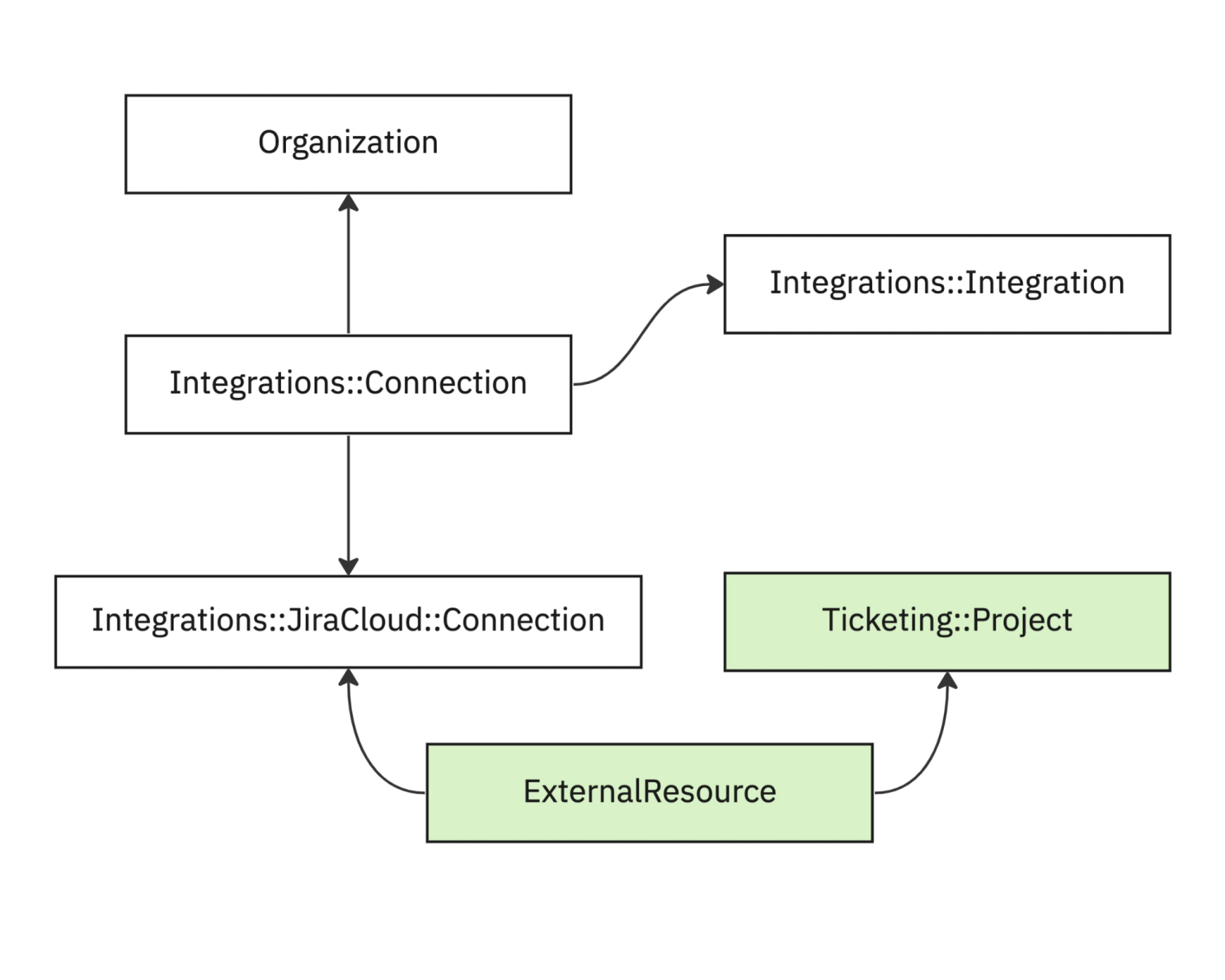
The ExternalResource model is how we accomplish associating data to other systems. The schema for it is:
The remote_id column is where we’ll store the unique identifier in the external API we’re integrating with.
Making integrations useful with actions#making-integrations-useful-with-actions
Simply connecting and syncing projects with a capability client gives our customers no value whatsoever. Mentioned above, customers want to create an incident ticket when an incident is opened. This is where we tie integrations to our powerful Runbooks engine in the form of “integration actions.”
CREATE TABLE public.integrations_actions (
id uuid DEFAULT public.gen_random_uuid() NOT NULL,
name character varying NOT NULL,
slug character varying NOT NULL,
description character varying NOT NULL,
integration_id uuid NOT NULL,
config jsonb DEFAULT '{}'::jsonb NOT NULL,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
automatable boolean DEFAULT false NOT NULL,
repeatable boolean DEFAULT false NOT NULL,
discarded_at timestamp without time zone
);FireHydrant Runbooks are extremely flexible because of the way we’ve built their steps into the actions provided by connected integrations. Take a mental note of the “config” JSONB column in the schema above. Our Runbooks architecture is a post in itself, so we’re focusing on how integrations work with them.
Similar to how integrations are defined, we have another file called “actions.yml” that contains every integration action we support (it’s a very long file). These actions are defined matching the protocol buffer messages, similar to something like Kubernetes manifest files.
Here is the definition of the Jira Cloud action for creating an incident ticket:
- name: Create a Jira Cloud Issue
description: Creates an issue in Jira Cloud that references the incident
integration_slug: jira_cloud
slug: create_incident_issue
repeatable: false
automatable: true
supported_runbook_types:
- incident
config:
elements:
- id: project
type: DYNAMIC_SELECT
dynamic_select:
async_url: /runbooks/select_options/jira_cloud/create_incident_issue/project
clearable: true
required: true
- id: ticket_summary
dataKeyName: ticket_summary
type: INPUT
input:
placeholder: "{{ incident.name }}"
default_value: "{{ incident.name }}"
label: Ticket SummaryThe “elements” key of the action is how we dynamically display configuration forms for steps when they’re being added to a runbook. This powerful design means that our runbook configuration screen doesn’t need to be modified when we add new integrations and actions.
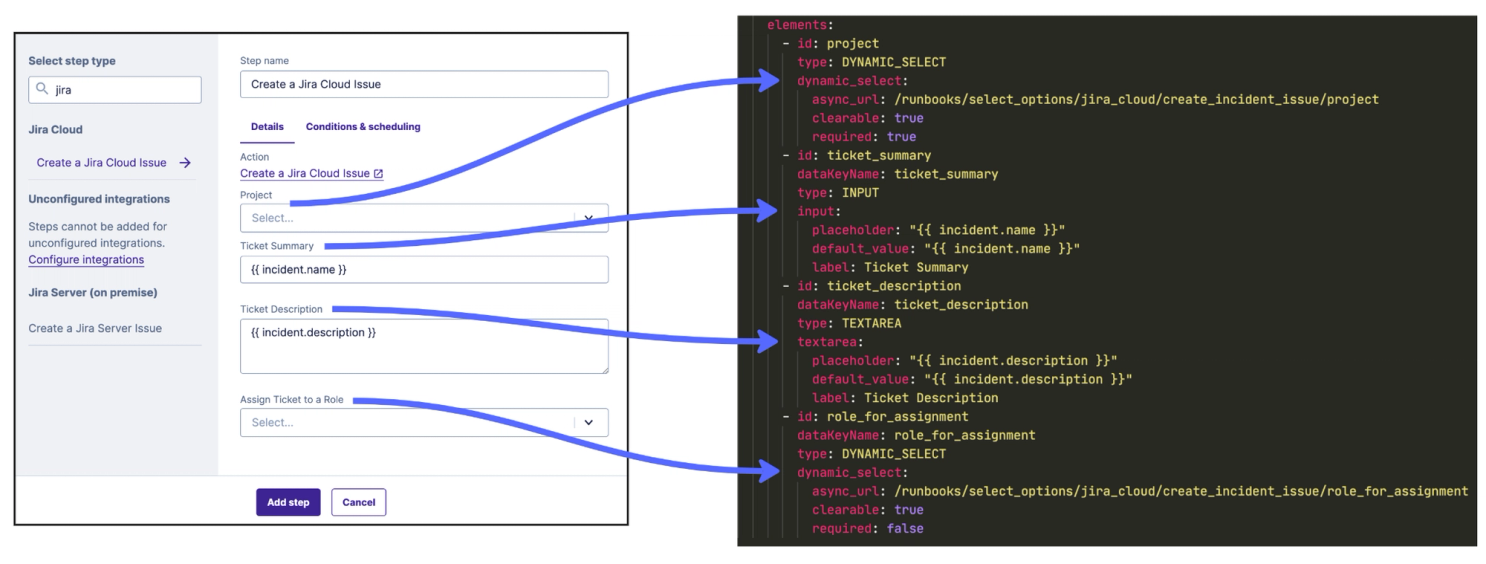
From YAML to React#from-yaml-to-react
This “Config as UI” pattern makes its way into our React frontend, giving users the form you see in the above screenshot.
import React from 'react';
import Text from '../components/stepElements/Text';
import Markdown from '../components/stepElements/Markdown';
import TextArea from '../components/stepElements/TextArea';
import Input from '../components/stepElements/Input';
import DynamicSelect from '../components/stepElements/DynamicSelect';
export const elementTypeComponents = {
PLAIN_TEXT: data => <Text {...data} />,
MARKDOWN: data => <Markdown {...data} />,
TEXTAREA: (data, name) => <TextArea {...data} name={name} />,
INPUT: (data, name) => <Input {...data} name={name} />,
DYNAMIC_SELECT: (data, name) => <DynamicSelect {...data} name={name} />,
DIVIDER: (_data, _name) => <hr />,
CONTEXT: (data, name) => <Context {...data} name={name} />,
};
export const buildElements = (elementArray, name, enabled) =>
elementArray.map((element, index) => {
const component = elementTypeComponents[element.type];
const isLast = elementArray.length === index + 1;
const field = `${name}${element.id}`;
const data = JSON.parse(JSON.stringify(element));
return (
<div className={`step-wrapper-${element.type} ${!isLast && 'mb-4'} ${element.type === 'INPUT' && 'Form__Input'}`} key {`${element.id}-${index}`}> {component(data, field)} </div>
);
});Runbook actions#runbook-actions
The main component of a runbook in FireHydrant is a “step,” an action taken when the Runbook is executed. Runbooks are effectively the definition and coordination of integration actions. The data model looks like this:
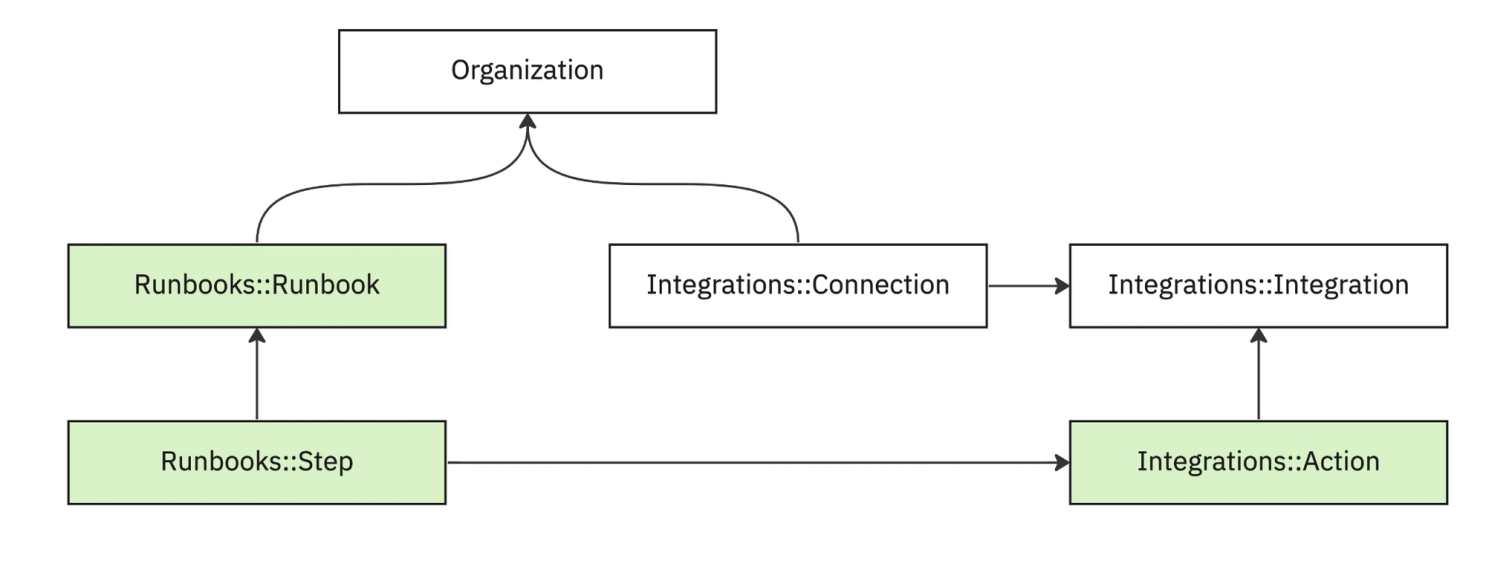
When FireHydrant processes a runbook step, we look up the integration action and subsequently look up a Ruby class that executes the class. Our step handlers, as we call them, are all registered using the format “integration_slug.action_slug” — this provides a humanized way to define steps. When the Runbooks engine looks up the action for creating a Jira ticket, it will search for “jira_cloud.create_incident_issue” and execute the logic for that class.
class ~Integrations~::~JiraCloud~::~Steps~::~CreateIncidentIssueStepHandler~ < ~Integrations~::~BaseStepHandler~
~def~ ~self~.~execute~(execution, step, actor)
# .. ~logic~ ~to~ ~create~ ~a~ ~ticket~ ...
~end~
~register_step~ 'jira_cloud.create_incident_issue'
~end~All of this comes together, and eventually a runbook step reaches its final destination: completion!
Recap#recap
Our entire design for integrations leans heavily into the Open-Closed principle. We've designed the engine to not require modification by looking for the right abstractions and enforcing them through conventions. This has allowed us to add and update integrations every month for the past three years and gives us confidence that we can continue to keep up with the ever-expanding universe of integrations.
What worked well for us (and hopefully will for you too) in designing an integration platform was considering the following:
- Create abstractions around the integration's core value proposition. For example: GitHub Issues, Shortcut Stories, and Jira Cloud Tickets are a “ticket” in FireHydrant.
- Separate your integrations from your core product as much as you can. The fast track to technical debt is having integration-specific code littered in your core product’s code.
- Have a source of truth for what the integration can do (e.g. “capabilities”). That way it becomes referenceable throughout the product much more easily.
If you're interested enough in software architecture to have made it here, chances are that software might fail sometimes. If that's the case, you could take FireHydrant (and the integrations we support) for a spin. It's free.