Featured
July 01, 2025
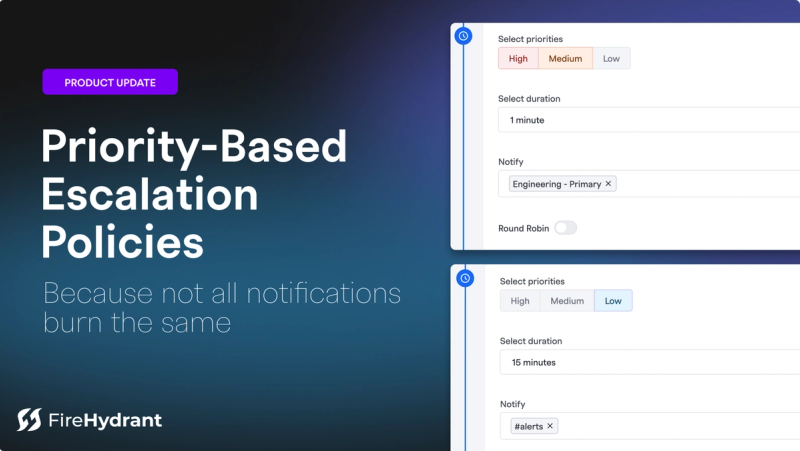
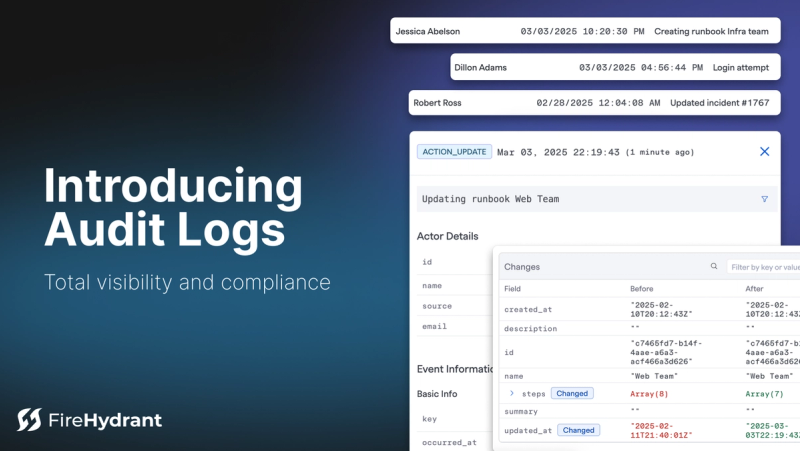
Signals Is Lighting Up the Future of On-Call: Eight (Yes, 8!) New Features Just Released
We’re going beyond notifications — and building the most powerful, flexible, and team-first on-call experience on the market.

July 01, 2025
We’re going beyond notifications — and building the most powerful, flexible, and team-first on-call experience on the market.