Blog
Insights, stories, and updates to help you build stronger incident response and reliability practices.
Blog / Page 4
Hot Take: Don't provide incident resolution estimates
By Robert Ross
|
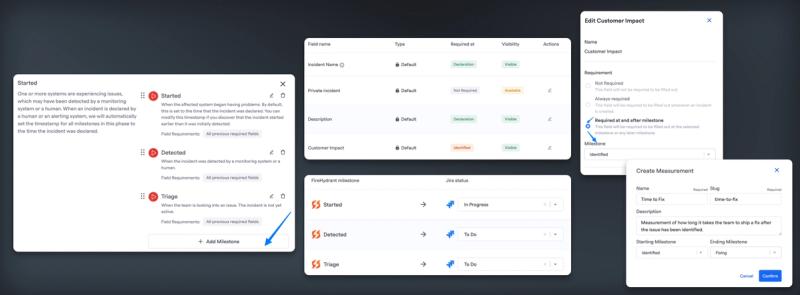
Custom Milestones: Empowering Enterprise Incident Management
By Jouhné Scott
|

SRE Culture [How to Build a Better Team]
By FireHydrant Team
|
Press Release: FireHydrant Acquires Blameless to Further Solidify Enterprise Market Leadership
By Robert Ross
|

Best Practices for Creating On-Call Rotations and Schedules
By FireHydrant Team
|

How to Improve On-Call with Better Practices and Tools
By FireHydrant Team
|

Semantic search with Ruby on Rails
By Robert Ross
|
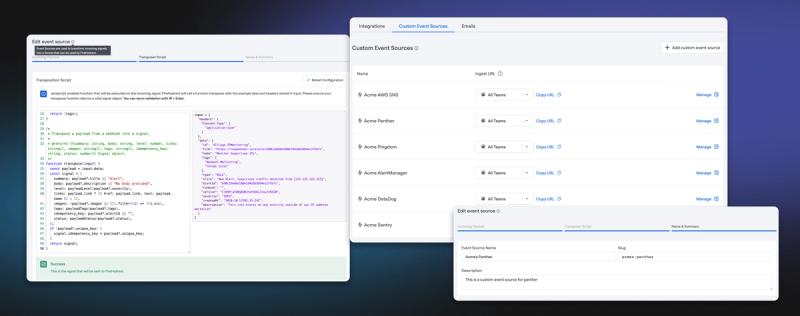
BYO Payload: Custom event sources for Signals have landed
By Robert Ross
|
Beyond the Headlines: The Unsung Art of Software Outage Management
By Robert Ross
|

SRE vs. DevOps vs. Platform Engineering
By FireHydrant Team
|

What is an Incident Timeline and How Do You Create One?
By FireHydrant Team
|
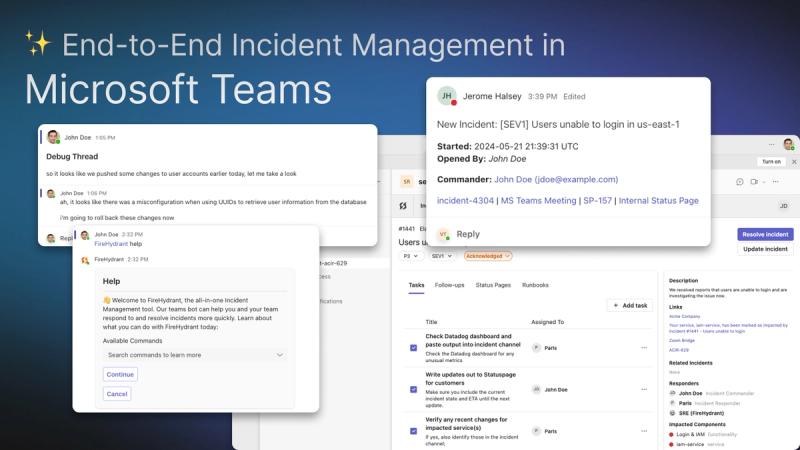
Introducing a Brand New Microsoft Teams Integration
By Danielle Leong
|