Blog
Insights, stories, and updates to help you build stronger incident response and reliability practices.
Blog / Page 5
Speedrun to Signals: automated migrations are here
By Wilson Husin
|

Incident Management Automation - What You Should Know
By FireHydrant Team
|

What are Blameless Retrospectives? How Do You Run Them?
By FireHydrant Team
|

Incident Response Team | Roles & Responsibilities Defined
By FireHydrant Team
|

Incident Tracking - How It Works & Why It Matters
By FireHydrant Team
|
FireHydrant is now AI-powered for faster, smarter incidents
By Robert Ross
|
Inside the gamedays: how we tested Signals for reliability
By Danielle Leong
|
3 Questions to Ask When Choosing DevOps Automation Tools
By Robert Ross
|

Finally: alerting and on-call scheduling for how you actually work
By Robert Ross
|

What Is Incident Management in ITIL? Best Practices
By FireHydrant Team
|
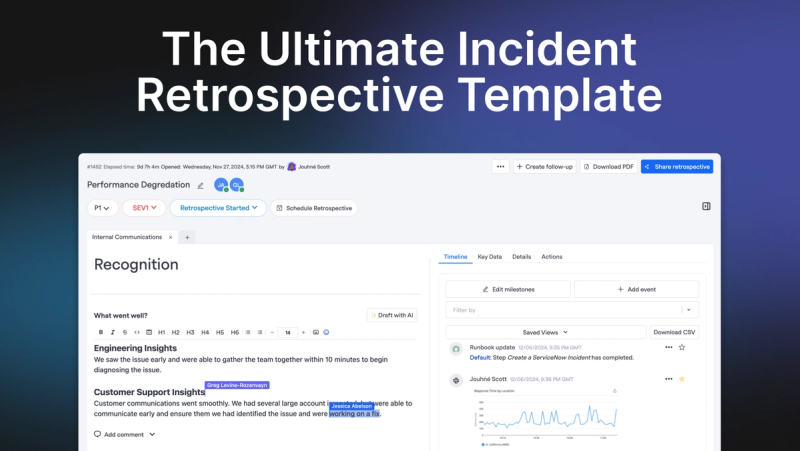
The Ultimate, Incident Retrospective (Postmortem) Template
By FireHydrant Team
|

What is Site Reliability Engineering [Simple Intro to SRE]
By FireHydrant Team
|