The MTTR that matters
We're over MTTR(esolution), but have you thought about MTTR(etro)?

“Mean time to X” is a common term used to describe how long, on average, a particular milestone takes to achieve in incident response. There’s mean time to detect, acknowledge, mitigate, etc. And then there’s the elusive “mean time to recover,” also known as “MTTR.”
MTTR, a hotly debated acronym and concept, measures how long it takes to resolve an incident on average. The problem with MTTR, though, is that it doesn’t matter.
MTTR is an excruciatingly flawed metric that relies on comparing fundamentally different incidents with different contributing factors to measure whether a team improves its incident response. It’s like putting together a Volkswagen Jetta, a BMW M5, and a Lamborghini on a race track and saying the average of cars is 80mph an hour. The brutal reality is that incidents will always vary in how long they take to resolve, so attempting to average different incidents of varying severities across a complex system will yield a number that has a high degree of variance as well.
Alas, several organizations still use MTTR to measure how they’re performing in their incident response.
What can we measure then?#what-can-we-measure-then
There are a few MTT*s I believe are valuable in incident response. Many of which can be quickly identified and acted on. I have an affinity to measuring MTTD or mean time to detect, which can reveal gaps in monitoring or thresholds in service level objectives that may need adjusting. But there’s one particular MTT* that can have a material impact on your team: MTTR.
Wait, what?#wait-what
“Wait, the one you just said not to use?”
Yes, fair question. Unfortunately, we only have so many letters in the alphabet, so MTTR stands for Mean Time To Retrospective in this acronym. Retrospectives being the gifts they are, have an expiration date. Retros are like a fruit basket, and you need to start getting into them quickly, or you might as well throw it away after a week.
So, why Mean Time To Retro?#so-why-mean-time-to-retro
When they inevitably arise, incidents create an opportunity for learning about your technical system, social graphs, and mental models the team may have. But it would help if you took advantage of them quickly or they spoil.
Hermann Ebbinghaus studied memory loss in the 1880s and created what is called The Forgetting Curve. He discovered that memory loss occurred rapidly over the first few hours or days but showed a more steady, gradual decline over subsequent days, weeks, and months.
When an incident occurs, our brains can go into overdrive while people debug, write communications, etc. Maintaining a timeline is essential, but the small details of an incident are nearly impossible to capture. It’s hard to capture what you were thinking at a specific point in time based on a single log line you spotted. Small details in incident response are the shavings that make a pile in a great incident retrospective, but as Ebbinghaus discovered, details can quickly be forgotten.
Because we forget things so consistently as time goes on, teams must hold a retrospective as close to the resolution as possible.
How to calculate Mean Time To Retro#how-to-calculate-mean-time-to-retro
The formula to calculate mean time to retro is almost as simple as they come:
- Note when you officially resolved the incident (resolution timestamp)
- Note when you have a completed retrospective (publish timestamp)
- Subtract the resolution time from the retro completed time to get the duration of how long the “retro gap” was

Once you have this information, you can start to calculate the mean time to retro over time, and ideally, this number begins to trend downward. It’s unrealistic to think this number will ever dip below 24 hours. Still, by including information such as the severity level, you can begin to see which incident severities are taking longer / shorter.
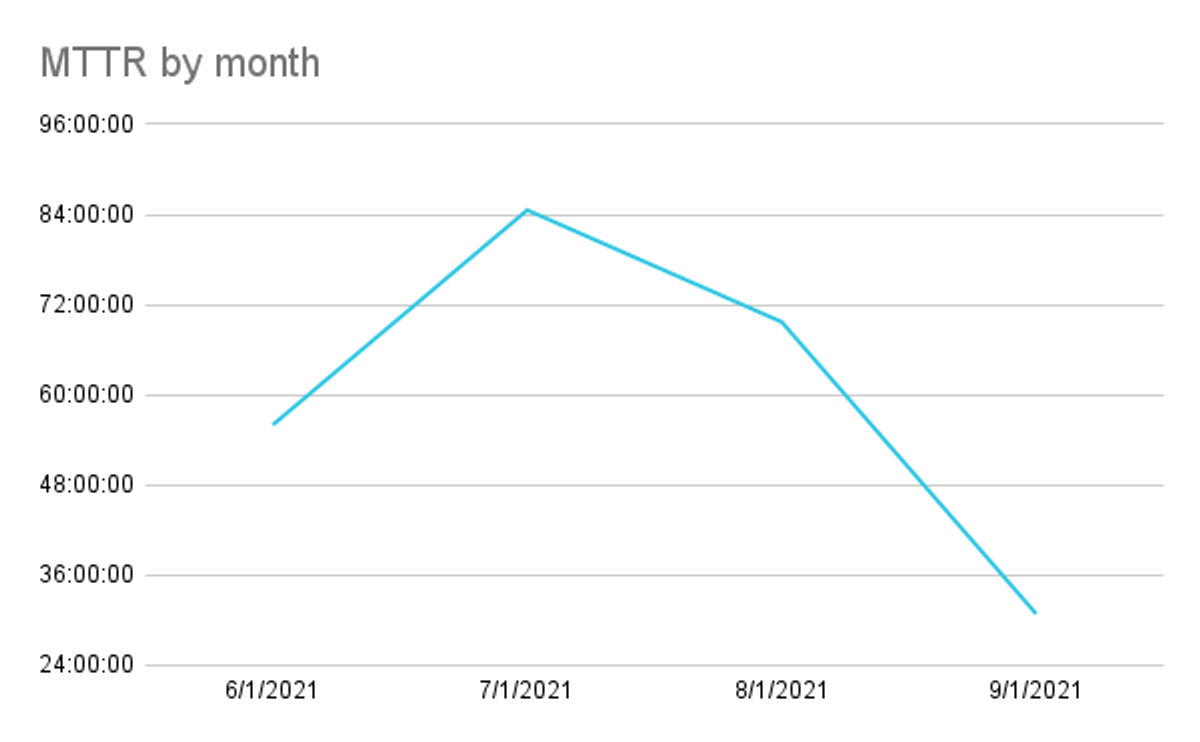
The value of a retro gap average#the-value-of-a-retro-gap-average
Having an idea of how long retros are taking is a measurable way to hold teams accountable for holding retrospective meetings at all. By inspecting what we expect, we normalize holding retrospectives as quickly as possible. Teams now have the tool to say, “Hey, I have to cancel or skip this meeting to hold a retro for that SEV1 we had yesterday” because it’s a measured number. Paving calendars to hold retrospectives can and should be normalized; measuring the retro gap from resolution helps achieve that.
Change what you’re measuring#change-what-youre-measuring
While it’s easy to follow the industry standard of that other MTTR, a little tweak to what the “R” stands for can help your team go even further - so measure the MTTR that matters - measure how long it takes to publish a retro.