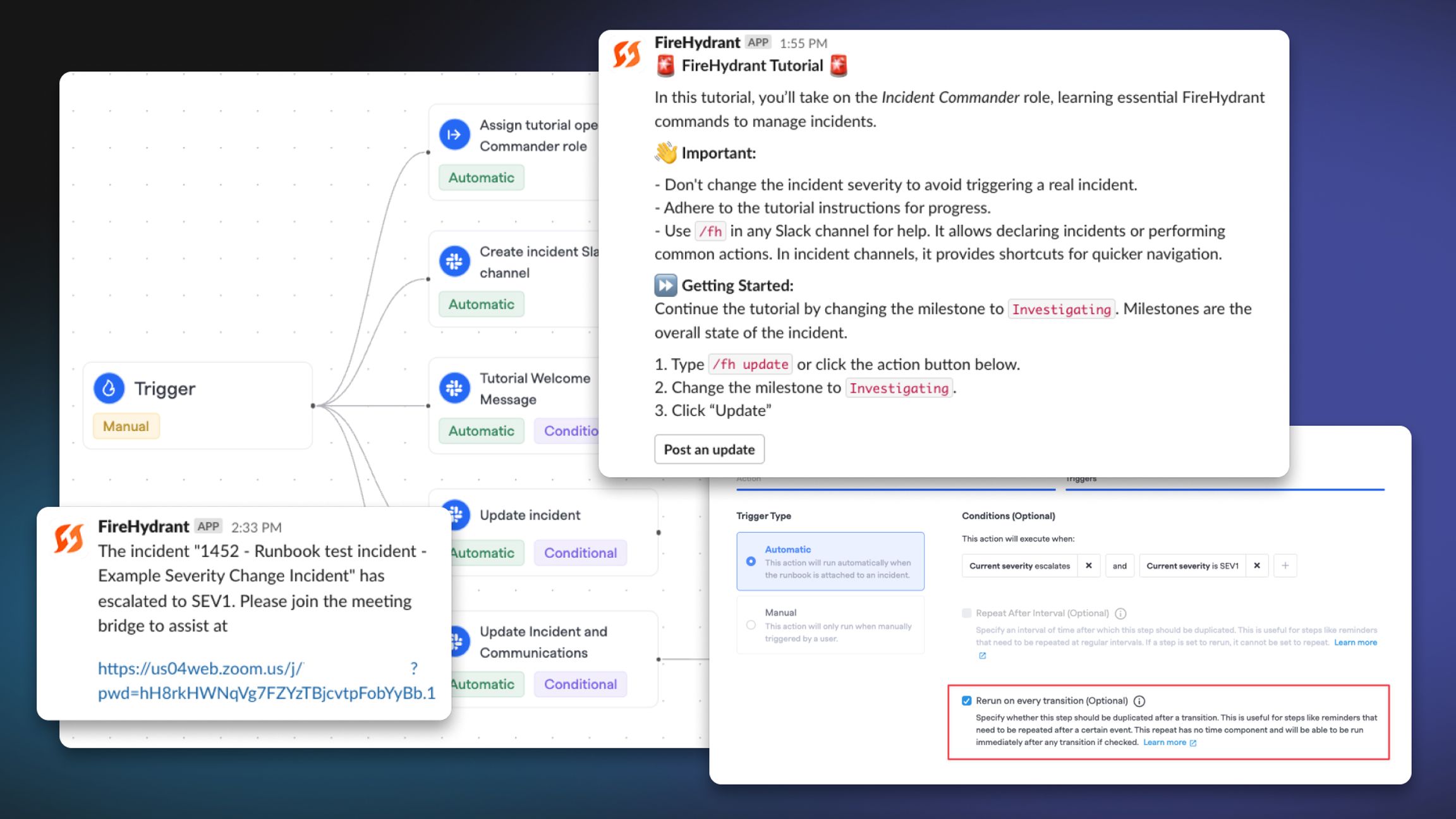
Tutorial Runbooks#tutorial-runbooks
Capitalizing on the flexibility of FireHydrant's Runbooks, you can now define your own Tutorial Runbooks (or start from a template and customize) for your responders to refer to whenever needed.
Once configured, check the setting for "Use for tutorial incidents" and it will automatically execute whenever users run /fh tutorial command in Slack or @FireHydrant tutorial in Microsoft Teams.
This also prevents it from accidentally attaching to real incidents, and you can update the Runbook as needed for whenever your processes change.
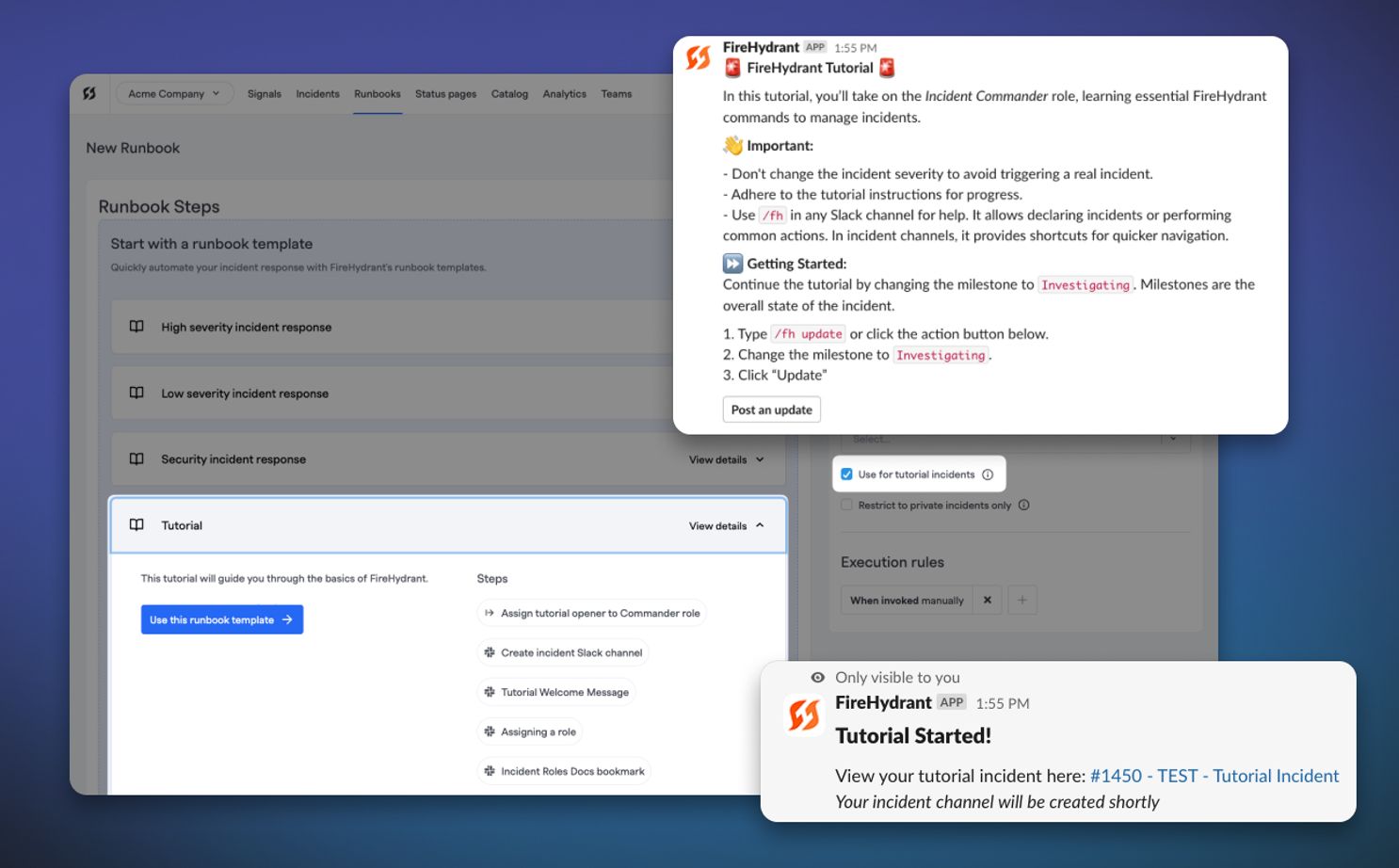
Visual Runbook Explorer#visual-runbook-explorer
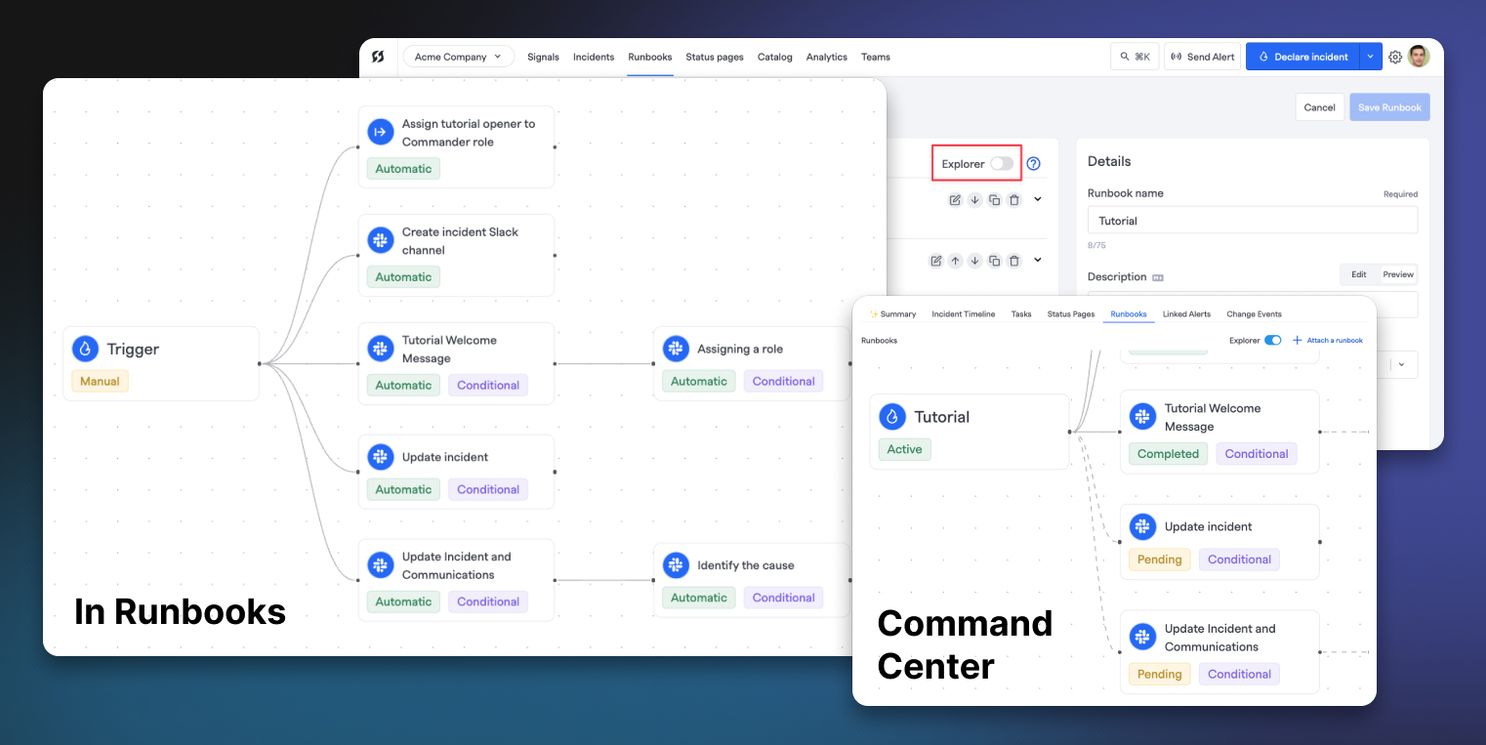
We've introduced a tree view for Runbooks. When configuring Runbooks or viewing a Runbook's execution in the Command Center, there is now a switch present with the "Explorer" label. Toggling this changes the view to the visual tree. You can also add and edit steps from within the explorer pane as well.
For people who are more visually-inclined, now it's easier to see how steps may depend on each other for completion and what executes immediately after incident trigger.
Automatically Rerun State Transition Steps#automatically-rerun-state-transition-steps
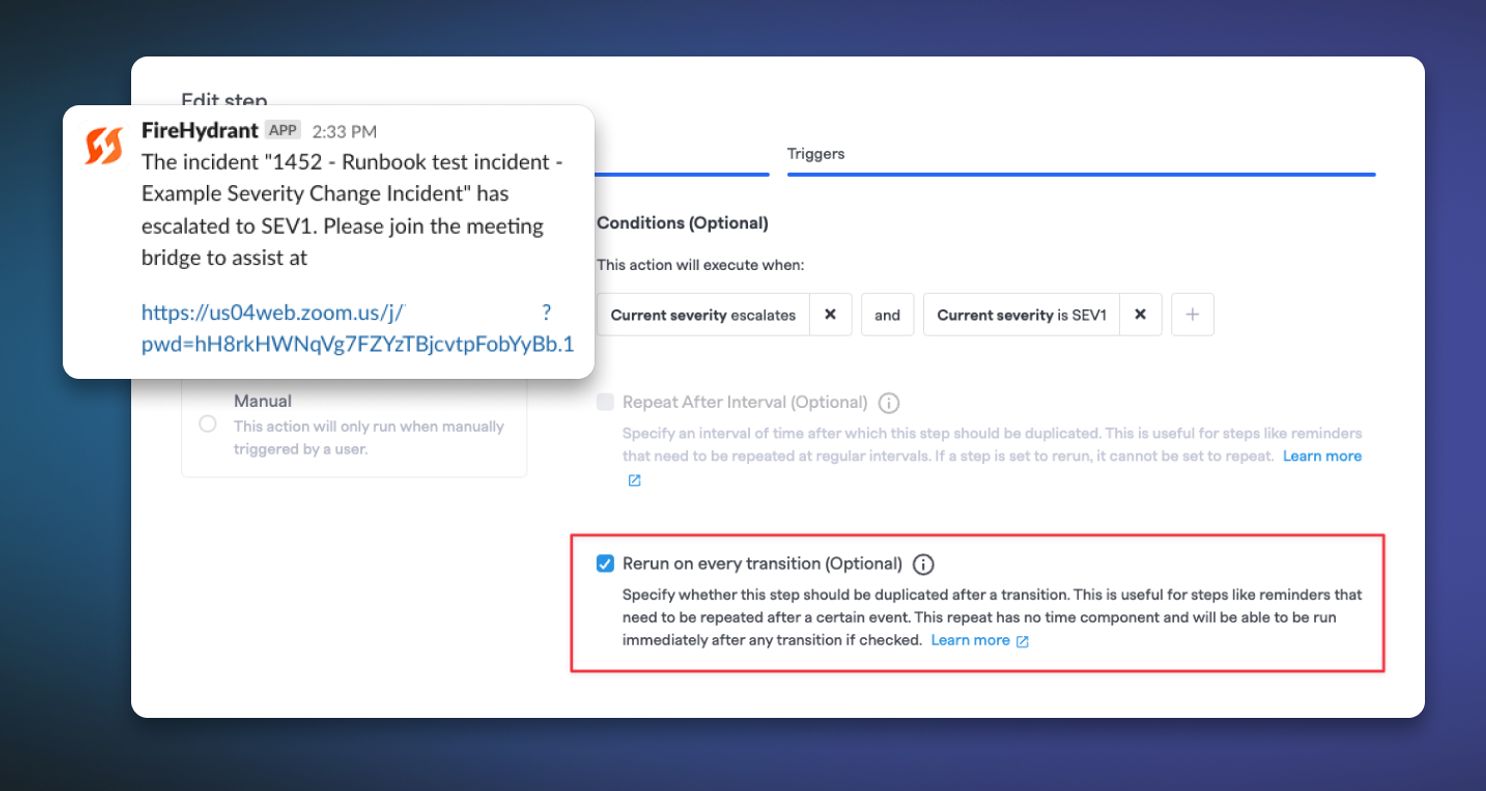
Rounding out our improvements to state transitions in Runbooks, any steps with state transitions as conditions now have an additional checkbox to "Rerun on every transition (Optional)". You can use the automatic step rerunning with the Attach A Runbook step to automatically re-attach runbooks on state transition.
Please note that not all steps support rerunning! Runbook steps that previously supported repeating are supported here, as well as a couple additional ones like renaming your Slack channel and attaching a Runbook.
Runbook steps traditionally could only be rescheduled every five minutes at the shortest, but this option enables steps to fire immediately upon transition. So now, you'll be able to do things like:
- Send an email out every time the Milestone changes
- Notify a Slack channel if the Severity upgrades or downgrades
- Send a webhook to your logging tool that the incident changed Severity
We hope this capability helps satisfy our customers' needs around ensuring updates are sent to custom locations in a timely manner!
Datadog Service Import#datadog-service-import
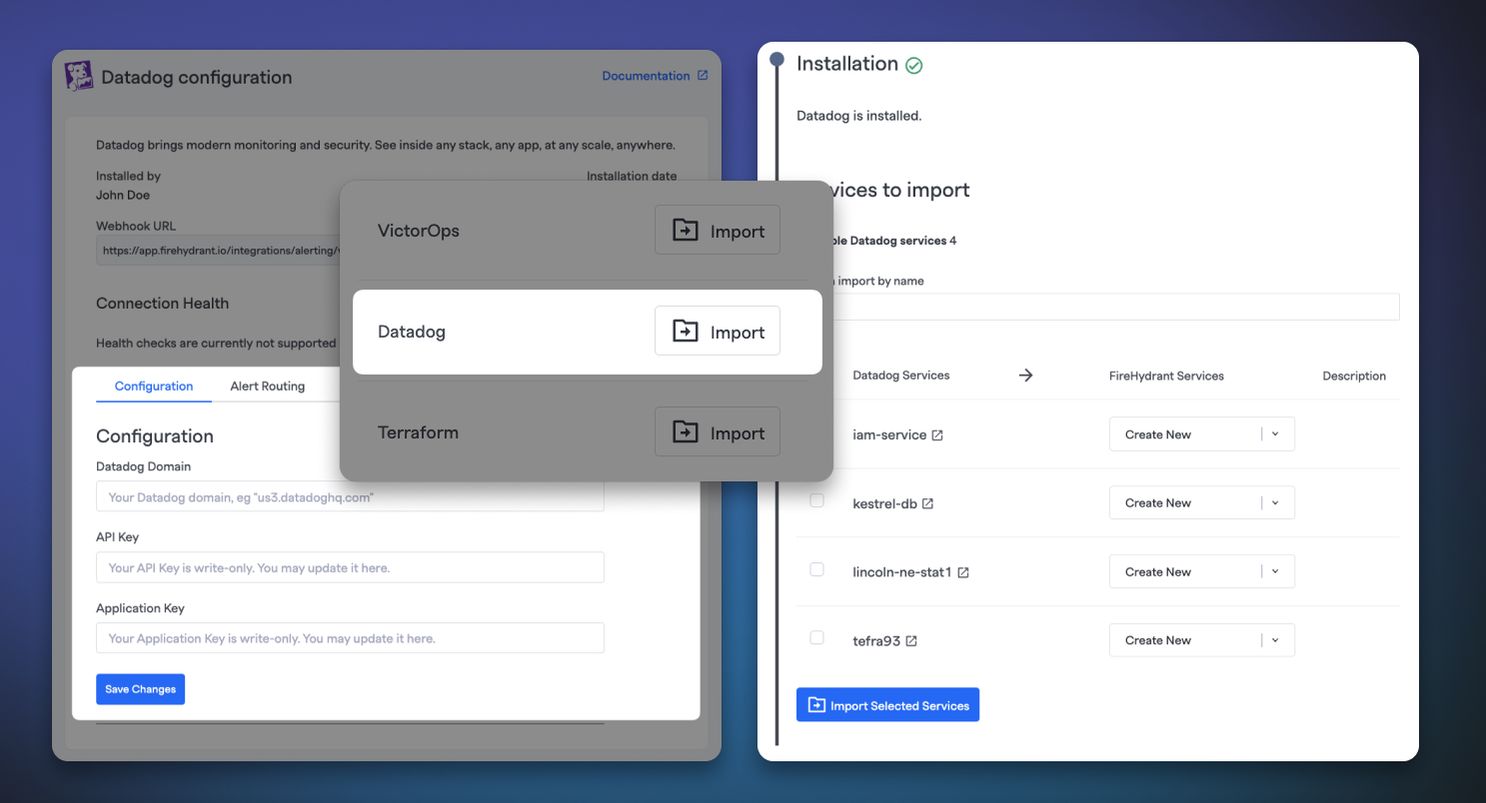
You can now import Service Catalog components from Datadog! To get started, you'll need to update the Datadog integration settings in FireHydrant with API and Application keys. Once done, head over to Catalog > Import from third party, and you'll see Datadog as an option.
Depending on how many services you have, it may take several seconds to load all of them. From there, you can decide whether to link them to existing components or to create new ones!
Other Improvements and Bug Fixes#other-improvements-and-bug-fixes
- 💅 We've added a
displayNamefilter to our/scim/v2/groupsendpoint for SCIM, allowing scripts and automation to filter down the fetched list of teams by a team name - 💅 In Microsoft Teams, different users may be logged in to different FireHydrant organizations. We've shipped a change that prevents users logged into one organization from interacting with cards created for a different organization
- 💅 We've added transposers for Chronosphere and GCP Service Health, allowing you to ingest Events from these sources out-of-box for alerting in FireHydrant
- 💅 The On-Call Schedules page for a team will now always show on-call schedules in the order that they were created, ensuring consistency each time someone looks at the calendar
- 💅 We now support reordering conditions in the user interface. Reordering these will impact the order they are shown everywhere else across the platform, such as when marking a Service as impacted in Command Center or in chat apps like Slack or Microsoft Teams. This change also will prompt users to modify their severity in the web ui if they have a configured severity matrix.
- 💅 Customers have requested an additional Tier 0 for Services and Functionalities so we've added it to the list of available values
- 💅 The "Attach a Runbook" step can now be re-run on every transition, in line with the state change capabilities
- 💅 For Jira On-Prem/Server, Custom Fields based on Jira Assets are now mappable in custom field mapping
- 🐛 We fixed a bug where our AI Copilot was suggesting the same incidents multiple times. Now, if an incident has been suggested before, it won't be suggested again during an incident
- 🐛 There was an issue where default Jira issue types weren't selectable in Jira project configuration even after mapping custom required fields. This has been fixed
- 🐛 We fixed an issue in Microsoft Teams where a templatized notification message would not update with latest status and links until after an update was made on the incident
- 🐛 We fixed a bug where extremely long idempotency keys on inbound Events would throw an error and not ingest the Event at all
- 🐛 There was an inconsistency in behavior when users were attempting to search for incidents that contained numbers in the title which was addressed
- 🐛 Our Grafana transposer was not correctly copying over parameters to Signals annotations so we've fixed this
- 🐛 We had been expiring Alerts that exhausted all Escalation Policy steps and handoffs even if they hadn't reached the 24-hour open threshold. This has been fixed
- 🐛 Users were getting Liquid errors on valid templating. It turns out this is due to implementation differences between Ruby Liquid (what we use) vs. Javascript and other implementations. In our Liquid previews, we now display descriptive error messages and suggestions for workarounds for specific issues
- 🐛 We fixed an intermittent issue with the Notify Slack Incident Channel w/ Custom Message where the Action Button field was sometimes required and sometimes not. This is now consistently optional
- 💥 We've disabled the ability for an Escalation Policy to hand off to itself. This prevents an escalation path from running until the end of time, since your on-call responders won't live that long. Instead, we recommend using Repeats to rerun the Escalation Policy (a reasonable number of times).