Using PostgreSQL advisory locks to avoid race conditions
We used to see multiple incident declarations exceed our 3-second target each day. After this update, it became rare to see any at all.

The first moments of incident response can be among the most crucial, which in turn can also make them among the most stressful. There are many ways to ensure incidents are kicked off smoothly, but a recent focus of ours was to ensure they could be kicked off quickly. After all, the faster you're able to start mitigating your incident, the more successful you'll be!
We have a 3-second SLO for incident declaration that measures the amount of time it takes for you to declare an incident on FireHydrant. The 3 seconds is largely driven by Slack’s integration requirement, but is also a sensible target for our UI declarations, too. Three seconds may seem like a lot, but in a platform like FireHydrant incident declaration has a lot of moving parts. When someone declares an incident, we use a database transaction to prevent a late error from leaving data in a bad state. For most of our users, the entire incident declaration process doesn't come close to taking three seconds. However, we started to see more and more incident declaration requests exceed three seconds for the largest among them. As we monitored the slowest of these requests more, it didn't take long to pinpoint the problem: waiting for an exclusive lock our incidents table.
Incident #1, Incident #2, Incident #3…#incident-1-incident-2-incident-3
One of the first things FireHydrant has to do when an incident is declared is insert a row into the incidents table in PostgreSQL. To do this, our application generates a certain unique identifier (separate from the primary key) for the incident. Similar to how every GitHub repository gets an incrementing set of numbers for its issues and pull requests, each of our customers also gets an incrementing number to identify their incidents:
CREATE UNIQUE INDEX index_incidents_on_unique_number ON incidents
USING btree (organization_id, number);Typically, these incrementing numbers are handled by creating and using sequences in your database. For example, a standard sequence for an incident number or other automatically incrementing ID would look like this:
CREATE SEQUENCE public.incident_number_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE ONLY public.incidents
ALTER COLUMN number
SET DEFAULT nextval('public.incident_number_seq'::regclass);Unfortunately, while PostgreSQL is great at generating sequences of unique identifiers for a table, there's no built-in mechanism for scoping this sequence to, in our case, the organization_id column. The above sequence would be global, with each user seeing gaps in their own incident numbers.
Since FireHydrant's beginnings, our way around this limitation was to rely on a library built to solve exactly this problem: a Ruby gem called sequenced. With sequenced, all we had to do was add this to our Incident model:
class Incident < ApplicationRecord
acts_as_sequenced :number, scope: :organization_id
endOver the years, however, our product matured and became more complicated, and sequenced became a bottleneck for us.
Off to the races#off-to-the-races
As you may have surmised, generating an identifier that is unique only within a scope lends itself to a classic race condition. Consider this scenario: I work for a huge corporation, Acme, which has a robust incident management process. It isn't uncommon for multiple investigative incidents to be declared each day. The problem comes in when we try to declare more than one incident at exactly the same time. The problem comes back to incident declaration having many moving parts all occurring within a single database transaction, but generating this number is one of the first things to occur within the transaction.
Standard sequences are non-transactional, which means they can and will increment regardless of what occurs in a transaction. Our scoped sequence has no such power, though; it's based entirely on SELECTing the highest existing value and adding one. So that’s why when more than one incident is declared at the same time in a company, we're likely to end up in a situation where each transaction attempts to create an incident with the same number.
The sequenced gem avoids this race condition by acquiring a lock on the table in question; this lock forces other transactions to wait to generate their own incident number, ensuring that no two transactions ever attempt to reserve the same one. We discovered this behavior when looking into incident declarations that exceeded our three second target. Every slow transaction had the same problem: a long-running LOCK TABLE incidents IN EXCLUSIVE MODE statement that waited multiple seconds to acquire the lock. What's worse is that these exclusive locks were overkill. Generating incident numbers is only important when inserting new incidents, and it's only important within the scope of a single organization. An exclusive table lock, however, prevents (or must itself wait for) any and all other writes to the incidents table regardless of whether they were inserts, updates, or for incidents owned by a different other organization. We needed to narrow the scope of this lock so that one customer's incident declaration wouldn't block writes to the incident table for everybody else.
We immediately came up with a shortlist of options for solving our exclusive table lock problem, from least to most complex:
- Modifying the table locking statement to be less restrictive
- Creating a PostgreSQL
SEQUENCEobject for every organization using FireHydrant, and proactively creating them as new users sign up - Outsourcing incident number generation to a microservice that is built solely to increment numbers (e.g. something that would fulfillFly.io’s “Grow-Only Counter” Challenge)
While we recognized that third option was likely the best long-term solution to our problem, especially as we onboard more users and larger users, but we needed a solution that we could implement more immediately that would allow us more time in the future to focus on it. Meanwhile, option 2 would have us creating and managing a large number of objects outside of our typical ORM, using raw SQL. Additionally, it would cause gaps in incident numbers for every failed database transaction that results in an incident not being created, which could lead to confusion for users (”What happened to Incident #42?”). Meanwhile, the first option would be a relatively easy fix and would solve the problem for any case that didn’t involve a high amount of concurrency within a single, large organization.
A first attempt: SELECT ... FOR UPDATE#a-first-attempt-select-for-update
We decided to pursue this first option by replacing the LOCK TABLE incidents IN EXCLUSIVE MODE statement with a scoped SELECT statement containing a locking clause (i.e. SELECT 1 FROM incidents WHERE organization_id = $1 FOR UPDATE). To test this out, we forked the sequenced gem and modified the table locking logic so it would produce this more narrowly scoped lock:
@@ -50,9 +50,9 @@ def unique?(id)
private
def lock_table
if postgresql?
- record.class.connection.execute("LOCK TABLE #{record.class.table_name} IN EXCLUSIVE MODE")
+ build_scope(*scope) { base_relation.select(1).lock(true) }.load
end
end
def postgresql?I saw immediate results, but they weren't quite what we expected. While we were no longer seeing errant locks waiting for multiple seconds, we saw odd behavior with the SELECT ... FOR UPDATE statements in our monitoring tools. These queries were always reported to be very fast on their own, but every single statement was consistently followed by a gap of approximately 500ms before the next operation:
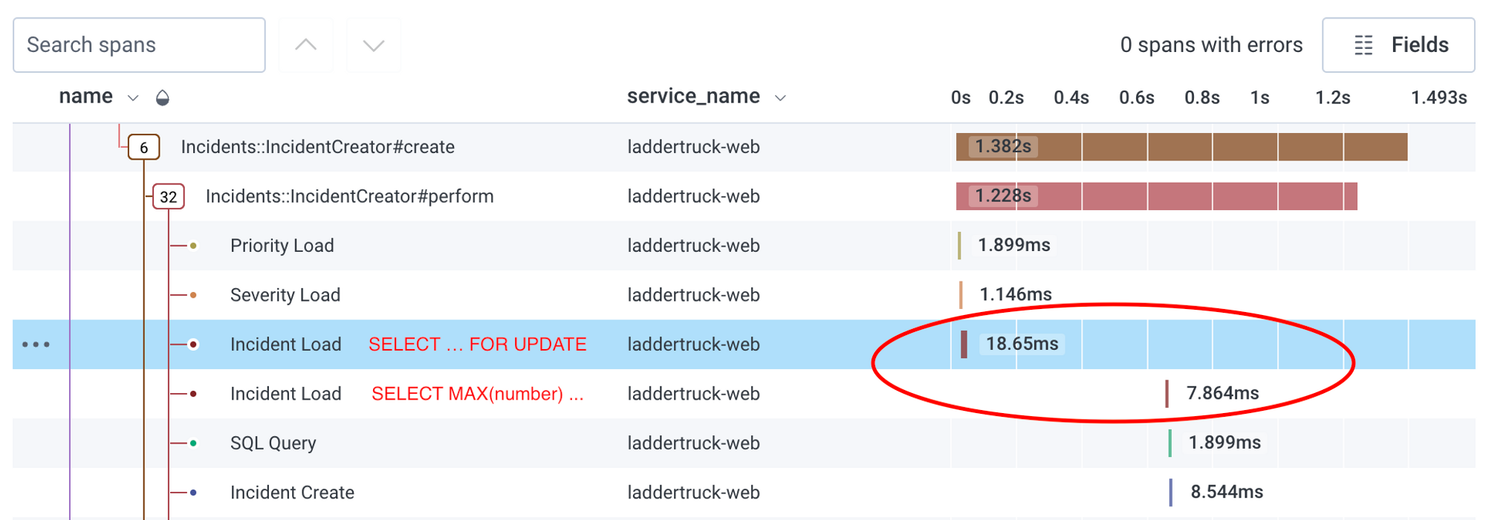
This appeared to be time that was completely unaccounted for, and we were unable to explain these gaps in our traces. While we attempted to investigate this, we ended up coming across a different locking mechanism that sounded like a better fit for our problem and quickly decided to try a different approach.
Advisory locks#advisory-locks
While reading more about PostgreSQL's various locking mechanisms, we found a feature we hadn't previously considered:advisory locks. In most cases, locks are enforced by the database, but advisory locks are different. These locks are tied to arbitrary identifiers and can be acquired by your application whenever needed, but it's up to the application to enforce their usage correctly. With advisory locks, we could use our scope (the organization_id column) to track one lock per organization, and only check this lock during our incident declaration transactions.
To test this out, we dropped our reliance on the sequenced gem and picked up a new dependency to add advisory locking support to ActiveRecord: the with_advisory_lock gem. Then, during incident declaration, we'd pull a transaction-level advisory lock that would only affect other, concurrent incident declarations within the same organization:
ActiveRecord::Base.transaction do
incident = organization.incidents.new(params)
# SELECT pg_try_advisory_xact_lock(...)
ActiveRecord::Base.with_advisory_lock_result(organization.id, transaction: true) do
incident.number = (organization.incidents.maximum(:number) || 0) + 1
end
incident.save!
# Lots of other stuff
end
# The advisory lock is automatically released here!After what happened with our FOR UPDATE locking clause experiment, we kept our expectations low... But, within days, it was clear that the results were exactly what we had originally hoped for. Whereas we used to see multiple incident declarations exceed our three second target each day, it became rare to see any at all; we now see only the occasional slow trace due to a single, large organization attempting to declare several, rapid fire incidents all at once.
We'll always be on the hunt for ways to improve our incident declaration times even more, but we hope the story of this specific victory can help you solve similar problems in your own application!