
Scoping your solution#scoping-your-solution
To effectively scope the right incident management solution for your team, you’ll want to pull in the right decision makers, map your process, and determine your tooling requirements. In this section, we’ll cover who to loop in, how to map your process, and what minimum requirements you want your tool to have.
Know your key decision makers#know-your-key-decision-makers
Understanding who your key stakeholders would be during the evaluation process will make your process much smoother when you’re deciding on the best incident management solution for your team.
From a leadership to everyday user, each of these people rely on and will have a say in the solution your team lands on:
- CIO, CTO. C-suite leaders are concerned with their strategy and high-level business goals, so factors like brand trustworthiness, security, product reliability are always top of mind. While they are removed from the day-to-day work their teams do, visibility is a major challenge. They rely on status reports, dashboards, and other updates to get insight into how things are going.
- VP Engineering, VP Ops. VPs ensure everyone in the engineering organization is successful and unblock issues. Business outcomes, productivity, scalability, and efficiency are important.
- Head of Site Reliability Engineering (SRE) or DevOps. The Head of SRE is responsible for managing the team that owns reliability within the engineering organization. They build and purchase tools that help them achieve greater reliability.
- Site Reliability Engineers (SRE). SREs champion efficient and effective incident management and are solely focused on building software that is focused on ensuring reliability of the product. They set up the framework for incident management, develop observability metrics, monitor and measure performance, and build solutions to improve reliability.
- System and Application Engineers. These engineers design and upgrade entire systems and/or develop the applications that run a business. Sometimes they also step in as on-call engineers, managing incidents that arise. Toil, growing backlogs, and a lack of process are their biggest challenges.
- Product manager, technical program manager, project manager. Product and program managers are responsible for the outcomes of reliability. If a retrospective results in 20 action items, they will be driving the completion of these items.
Other stakeholders#other-stakeholders
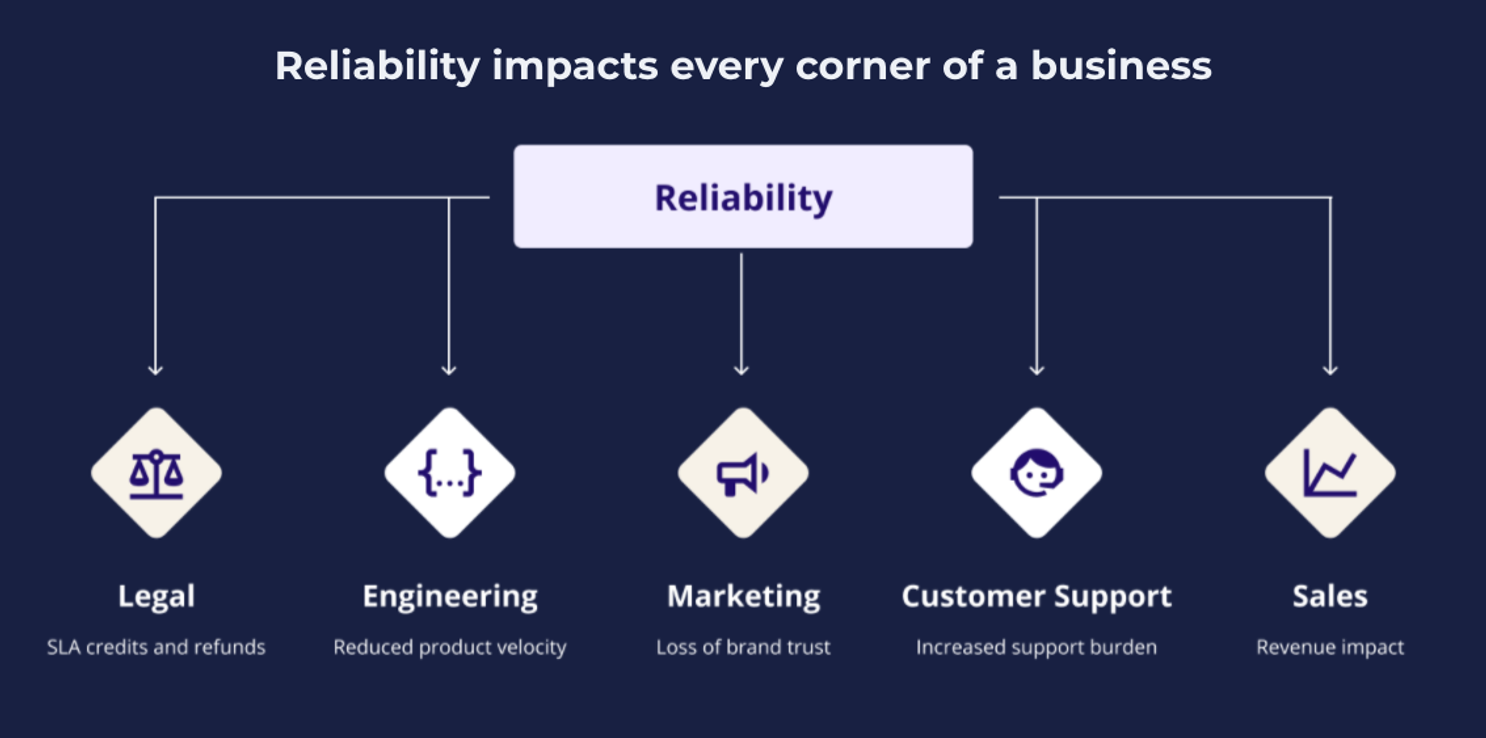
Incidents don’t happen in a vacuum. They affect customers and they affect different teams, outside the Engineering Organization, such as Customer Service and Sales. There will be a number of users that may not directly interact with your incident management tool, who will declare incidents and who will need to know the status of incidents. Having a standardized process for incident management is key.
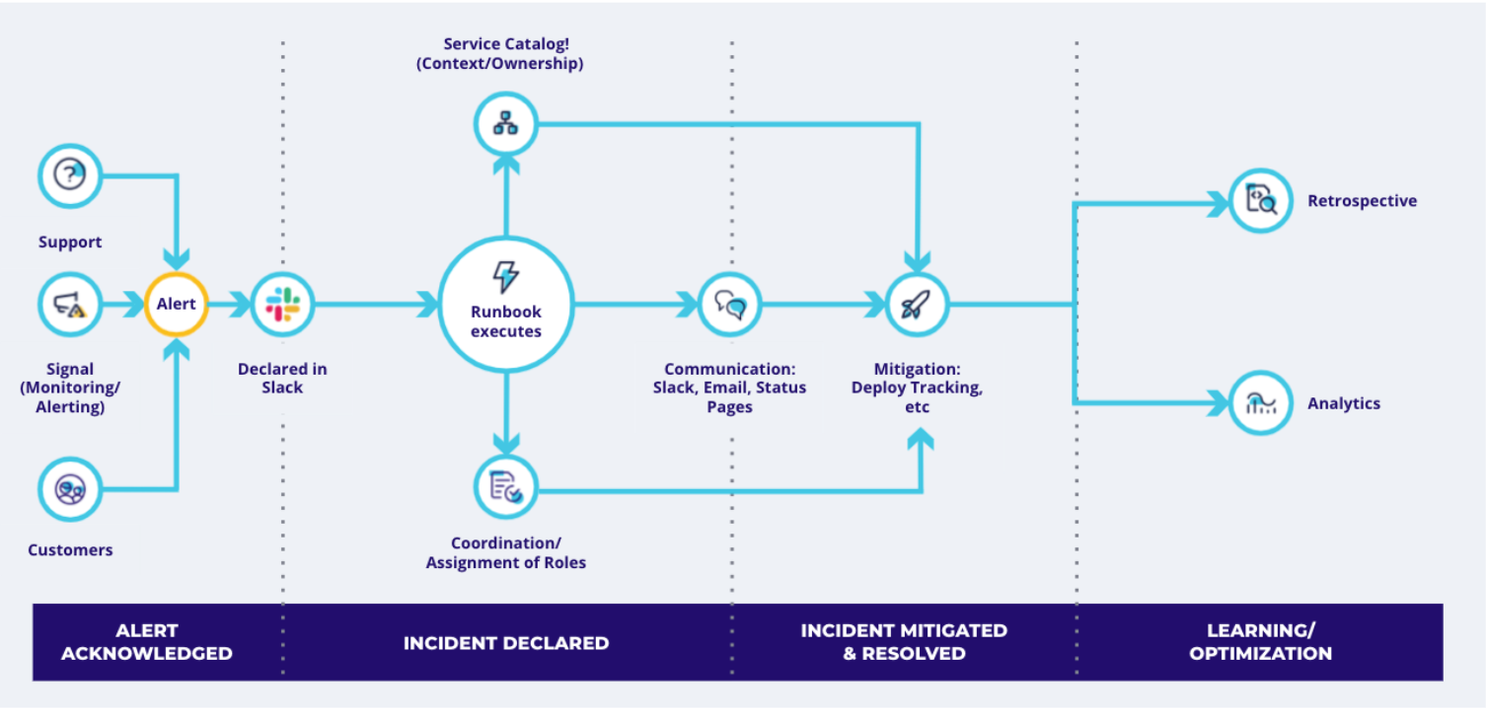
Mapping your process#mapping-your-process
Due to the maturity of tools available in the market to date, most incident response solutions live in the monitoring and alerting stages - but we’re all too aware that incident management doesn’t end there. When evaluating a solution, assess your entire incident management process and identify any gaps that you want to fill or areas where you can improve. Consider how you want your team and your work to evolve, how your company intends to grow, and how the tool you choose might support high alignment at scale.
Tooling requirements#tooling-requirements
Listed below are the features we believe are table stakes for a robust incident management solution.
Runbooks#runbooks
Runbooks enable you to turn existing incident response processes into repeatable, automatable best practices. Whether you base them on incident severity, system infrastructure, or incident role, having pre-defined Runbooks will allow your team to focus on the issue at hand without having to remember exactly what to do for any given incident. Runbooks help you scale as you become more mature in incident response; they give you the flexibility to handle hundreds of different processes.
Integrations#integrations
Most companies have a growing stack of tools to manage different processes, like Slack, Okta, Jira, and others. Your incident management solution should be the connective tissue that enables all of your tools to work together seamlessly, ingesting data from and pushing data to various applications. An incident management tool with good integration options lets you get started quickly and leverage the power of your existing toolset.
API access#api-access
Having open APIs allows teams to configure programmatic workflows and offer the ability to connect to existing systems. An SRE whose core job is to build software to make the product more reliable will need programmatic API access to their tools to achieve that. For example, to query incidents or list of services another team owns to power another part of your stack requires API access. Your tool should have an API so you can build on top of it. With reliability, you are standing on the shoulders of giants and if the giant can get you higher through programmatic access to behavior you want, that is a huge win.
Service catalog#service-catalog
You can’t fight a fire if you don’t know where it is! Effectively responding to incidents requires knowing where the incident is occurring and understanding how your system was built. Keeping track of your inventory, including different environments, services, and customer-impacting functionalities will empower your team to effectively respond, communicate, and report around an incident based on exactly what is impacted.
Service ownership mapping#service-ownership-mapping
If you know which teams own which services, you can identify subject matter experts (SMEs) quickly when an incident occurs. This eliminates the toil of figuring out which team to alert based on what’s impacted and identifying the person currently on call for that team.
Communications#communications
Status pages enable your team to communicate system status to both public-facing and internal stakeholders, customers who are wondering what is going on and need your product, the sales team who might be giving a demo soon, the legal team in case any refunds need to be issued for SLA breaches, the customer support team so they can effectively respond to tickets, leadership so they can manage appropriately, and so on. Status pages streamline your messaging, while letting responders focus on the issue at hand.
Analytics#analytics
Analytics around key metrics of the incident, whether that’s Mean Time To [x]*, who’s responding, and uptime of your inventory allows leadership teams to understand how the company is effectively responding to incidents and managing their systems. This also allows leadership the data to implement changes, as needed. *By the way, to be clear, at FireHydrant, we believe that MTT are shallow metrics that don’t capture the full depth of customer impact.
Severity assignment#severity-assignment
Automatically assigning a severity to an incident based on which customer is impacted, condition of a system, and more reduces the cognitive load for declaring an incident and having to revert to documents on what type of severity, and therefore process, to run.
Change tracking#change-tracking
According to Google, 80% of their incidents are from bad deployments or configuration changes. A change event log allows you to understand what changes are being made to a user’s different environments and services, and quickly identify which recent releases are actually breaking your systems.
Retrospectives#retrospectives
After an incident, when the dust has settled and your team has taken a breather, it’s important to run a retrospective to learn how you can improve your process. The purpose of a retro is to analyze an incident from start to finish with the goal of figuring out what went wrong, what went well, and what atypical problems might have surfaced. Small occurrences can lead to big changes, so any actionable observations made during a retrospective can lead to big improvements. Learn more about retrospectives here.
Continuous improvement#continuous-improvement
Your incident management tool should encourage you to take what you've learned and use it to build better processes. For example, having metrics around incidents across all of your integrations helps you identify incomplete action items and ensure that all of those items get finished.