Opsgenie Is Shutting Down: Why FireHydrant Is the Natural Evolution
Everything you loved about Opsgenie — and a whole lot more, with a seamless migration to get you there.

Opsgenie is shutting down. Atlassian has announced the deprecation of Opsgenie as a standalone product, pushing teams toward Jira Service Management.
Opsgenie set a high bar. For years, it helped teams respond faster and stay on top of incidents with reliable alerting and on-call management. At FireHydrant, we’ve always admired how Opsgenie modeled incident data and structured its workflows — it was one of the best in the game.
But as Atlassian sunsets Opsgenie and teams face the pressure to migrate, there’s a real decision to make: move into Jira Service Management, or find a new solution that fits your team’s needs and scale.
If you’re looking for something that feels familiar — but does a whole lot more — FireHydrant is your best next step.
Why FireHydrant is the Best Replacement for Opsgenie#why-firehydrant-is-the-best-replacement-for-opsgenie
At its core, FireHydrant Signals is a full-featured alerting and on-call platform that gives you everything you expect from Opsgenie — and everything your future teams will be glad to have.
You get:
- Modern on-call schedules and escalation policies
- Multi-channel alerting via SMS, voice, email, Slack, WhatsApp, push, and more
- Powerful routing logic with custom Alert Rules or direct targeting
- Heartbeats to monitor for silence and system health drift
- Incident response, retros, status pages, and analytics — built into the same platform
Let’s walk through how Signals works, and why FireHydrant is the ideal alternative now that Opsgenie is shutting down.
How FireHydrant Handles Alerts Like (and Better Than) Opsgenie#how-firehydrant-handles-alerts-like-and-better-than-opsgenie
Signals begins the same way Opsgenie did: with an event from your monitoring tools. FireHydrant accepts events from popular tools out of the box (Datadog, New Relic, Grafana, Honeycomb, etc.), or you can define your own custom event sources to normalize data into a unified event format.
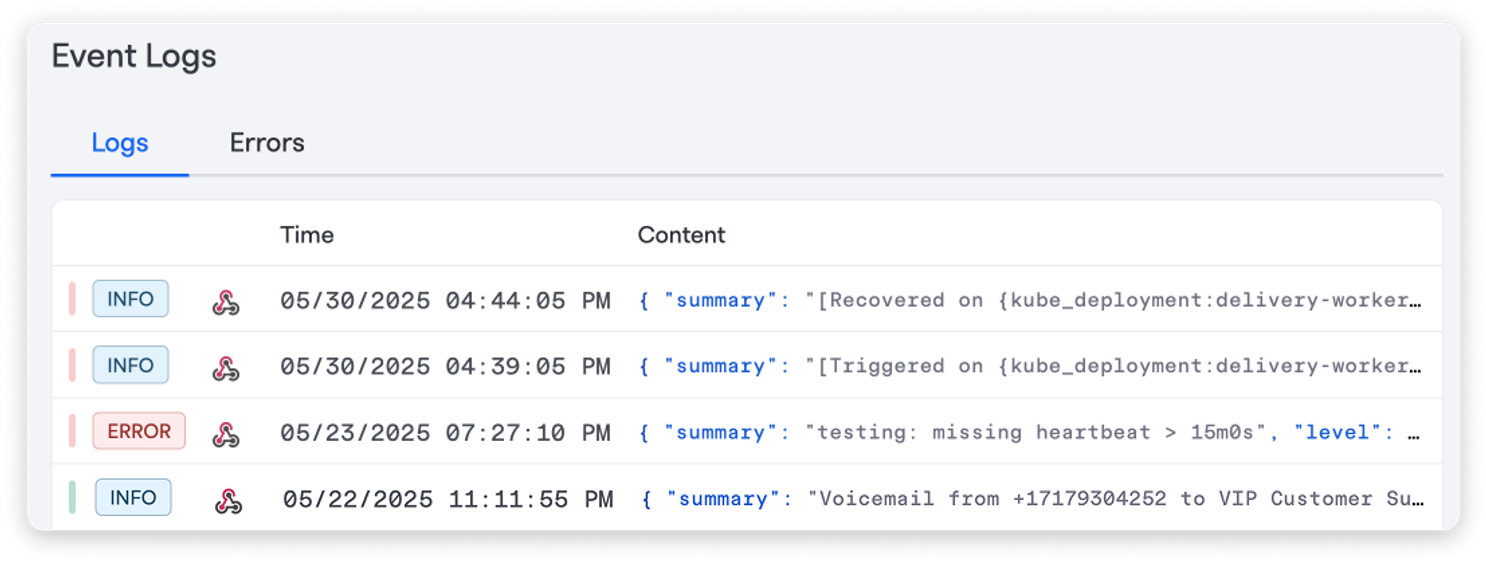
Every event is logged — whether it triggers an alert or not — giving you complete visibility across systems and tools. Unlike other on-call alternatives, not every signal becomes an alert, and not every alert becomes an incident.
By separating Events, Alerts, and Incidents in our data model, you get:
- Less noise: Only relevant signals trigger alerts, reducing fatigue and distractions.
- Smarter decisions: Responders can evaluate alerts before escalating to incidents.
- More accurate incident tracking: Multiple alerts can be associated with a single incident, giving you a fuller picture without duplicating effort.
- Better insight: Decoupling alerts from incidents gives you clearer data (like alert-to-incident ratios and mean time to detect) so you can fine-tune your rules and response.
Flexible Alert Routing with FireHydrant#flexible-alert-routing-with-firehydrant
With FireHydrant, you can build intelligent routing rules that match incoming event payloads to the right target, whether that's a user, a team, an on-call schedule, an escalation policy, or Slack channel.
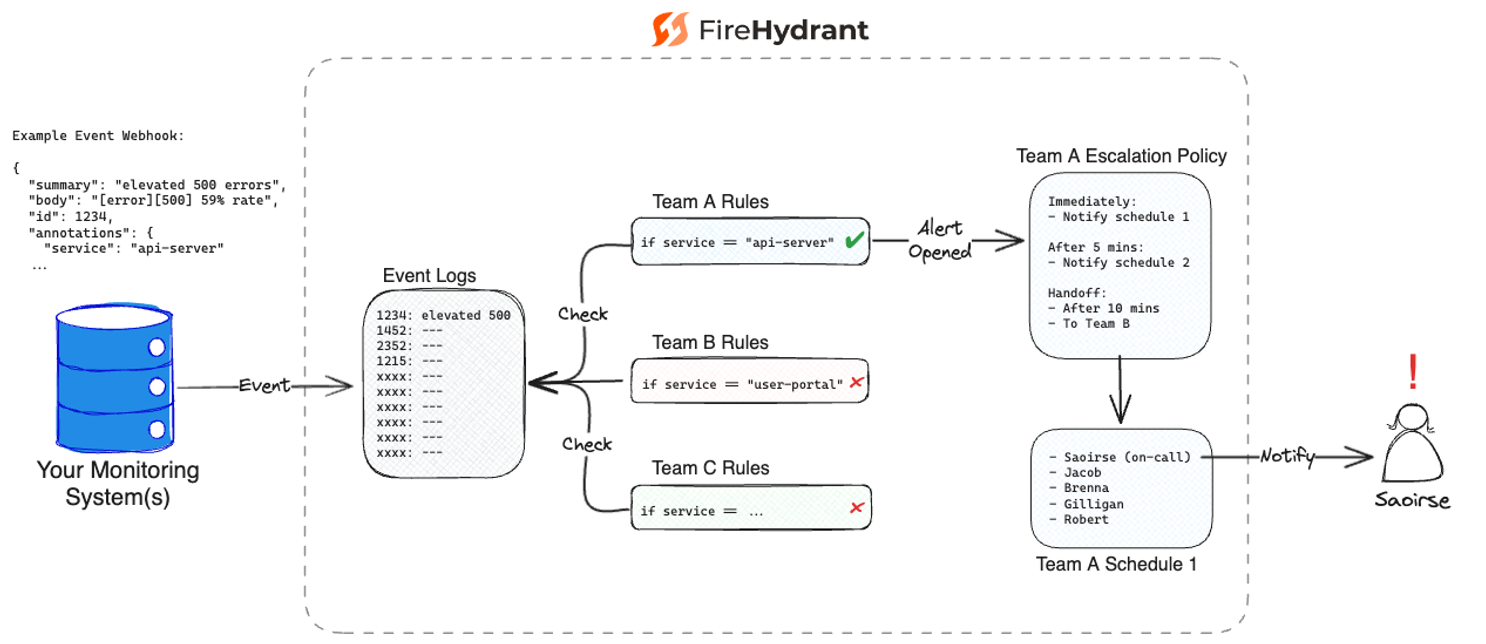
You can even skip rules entirely and route directly to a destination.
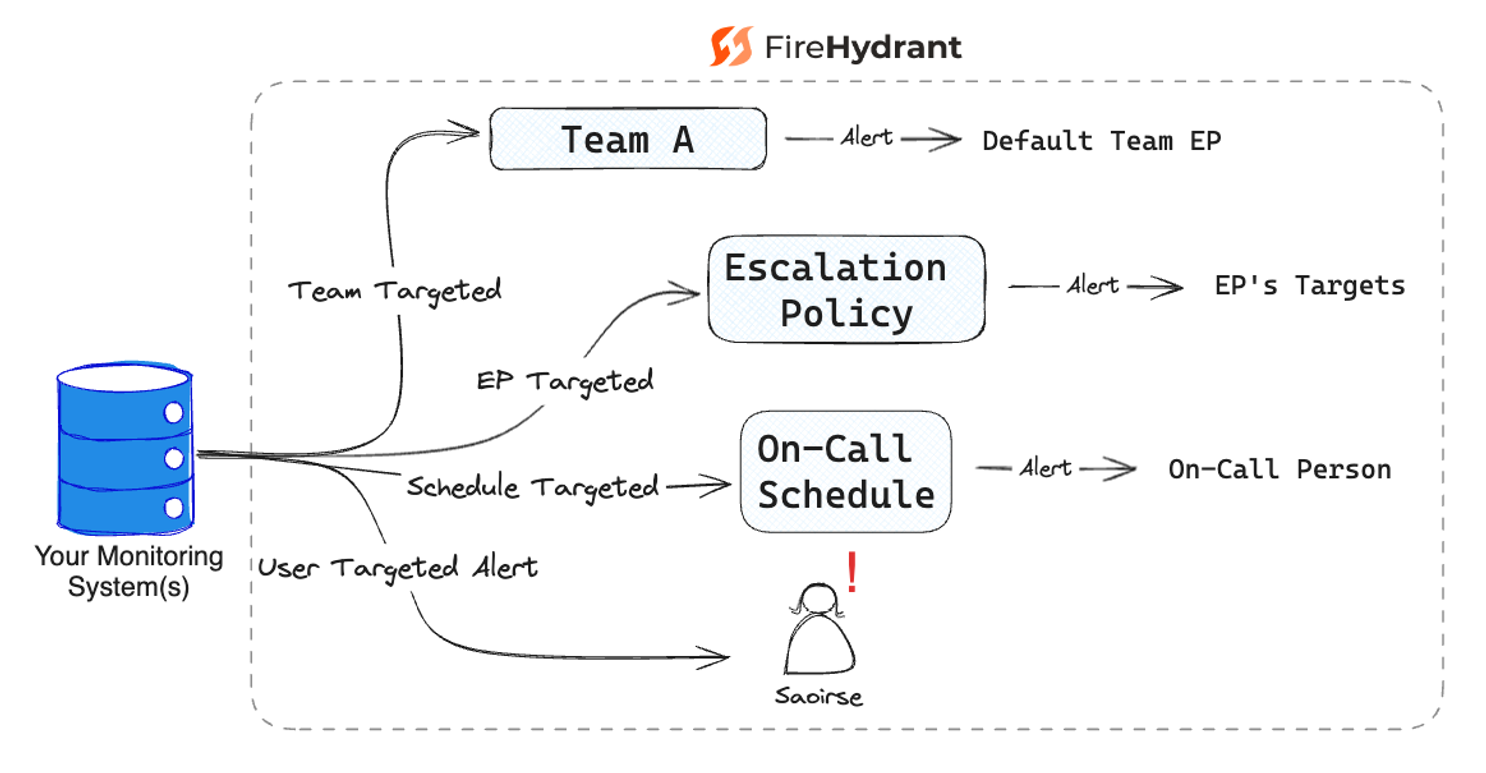
Either way, you reduce noise and make sure alerts land in front of the people who can act on them.
Smart Escalation Policies for Modern Teams#smart-escalation-policies-for-modern-teams
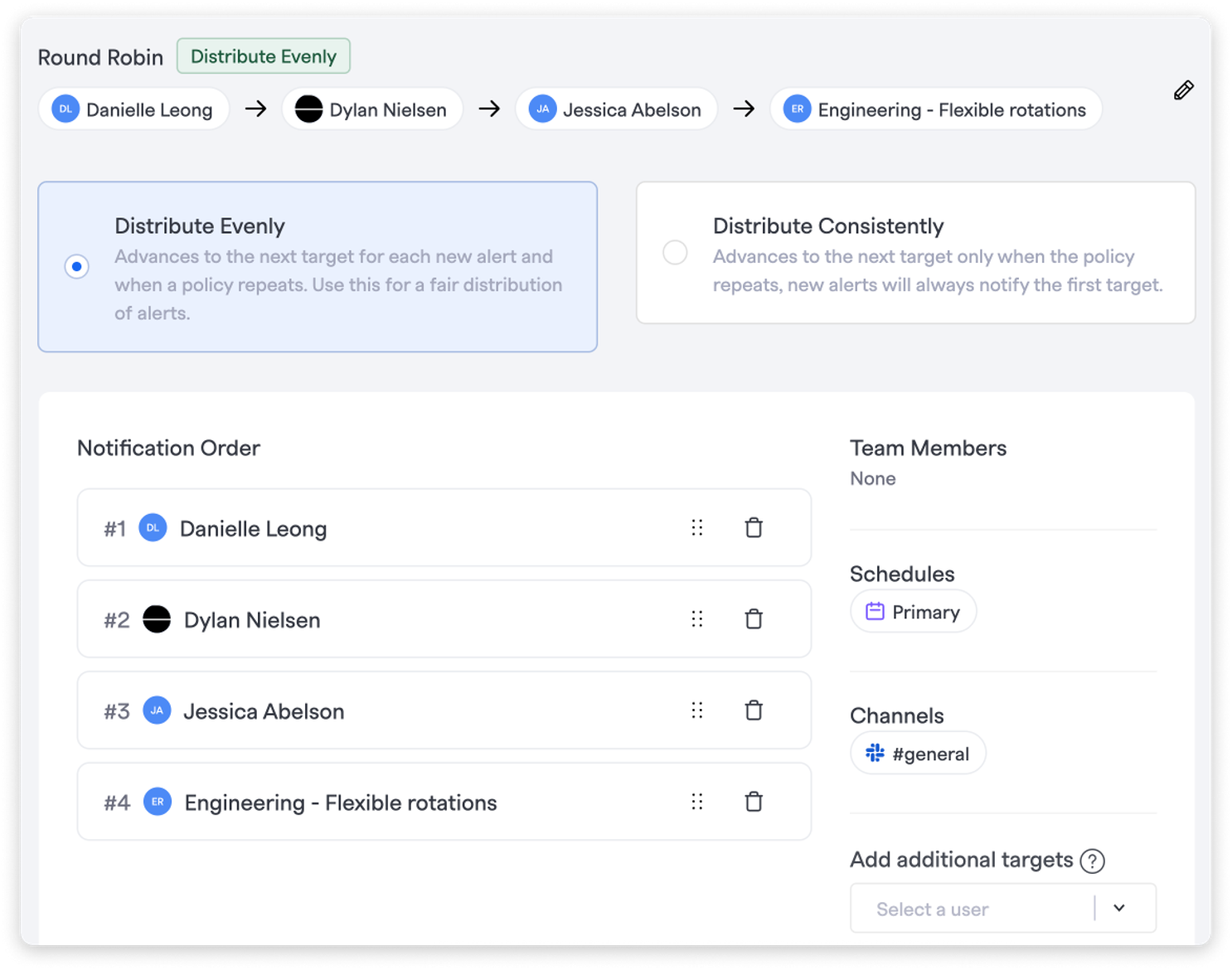
FireHydrant offers powerful, flexible escalation policies that ensure alerts reach the right people without delay or confusion.
With FireHydrant, you get:
- Flexible targeting: Target individuals, on-call schedules, Slack channels, or even page the entire team
- Round robin routing: Rotate alerts evenly across a group of responders to distribute load
- Delays between steps: Control how long to wait before moving to the next person or schedule
- Repeats: Retry the full policy multiple times if no one responds
- Handoffs: Automatically send the alert to a different team or escalation policy if all else fails
- Default policies: Set a go-to path for any incoming alert to your team
Whether you're paging for the first time or escalating across teams, FireHydrant gives you reliable, intelligent routing out of the box, so your team can stay focused on fixing, not figuring out who’s on call.
Reduce Alert Fatigue After Opsgenie#reduce-alert-fatigue-after-opsgenie
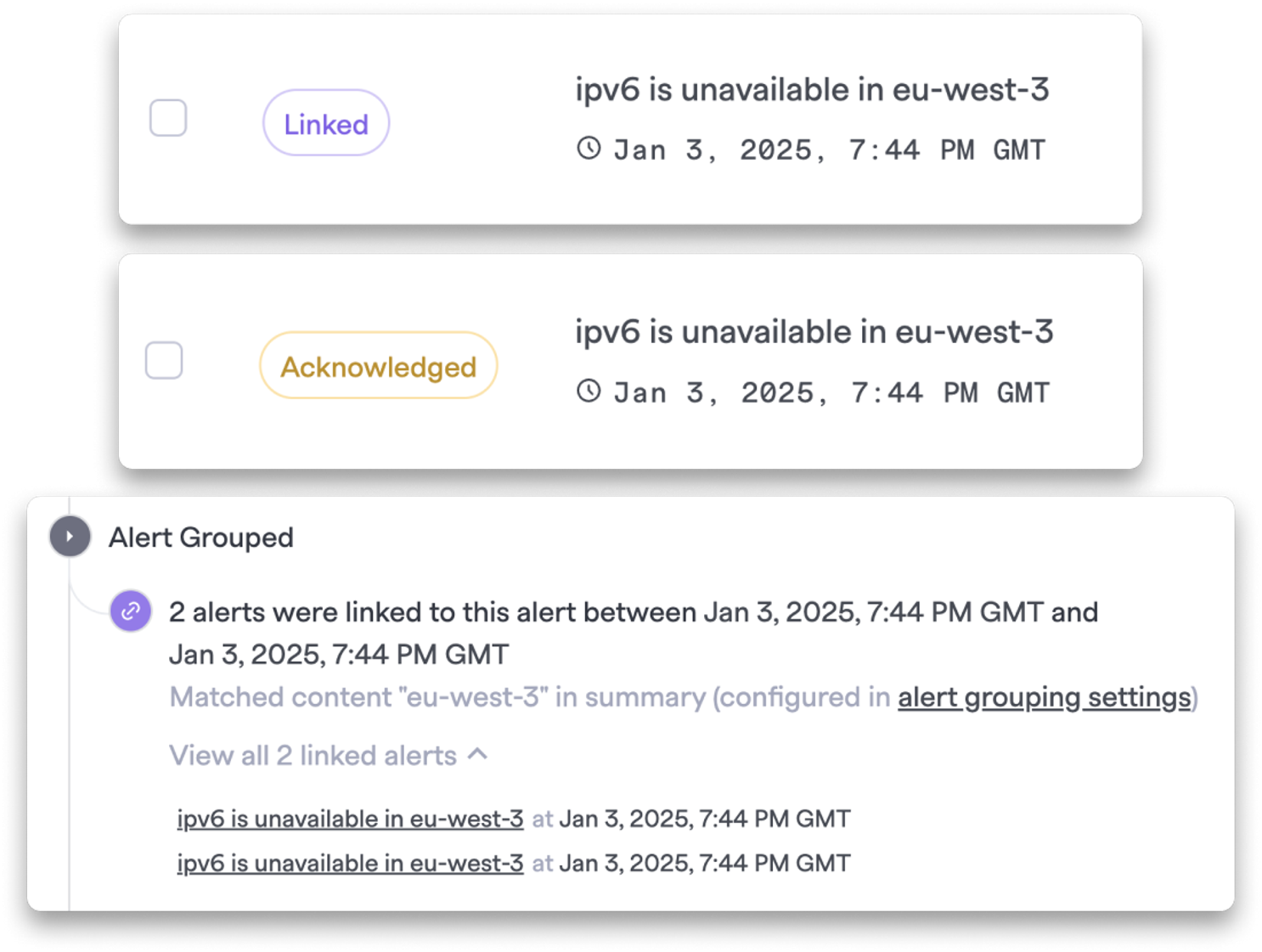
Tired of being paged for the same issue over and over? Alert Grouping lets you define patterns (summary, description, tags) and group similar alerts into one.
You control:
- How alerts are matched (e.g., error strings, service names)
- Time window (rolling or fixed) for grouping
- What happens to grouped alerts: link silently or send FYI-only notifications
This helps keep your team focused on what’s truly urgent, not flooded by duplicates.
Monitor Silent Failures With Heartbeats#monitor-silent-failures-with-heartbeats
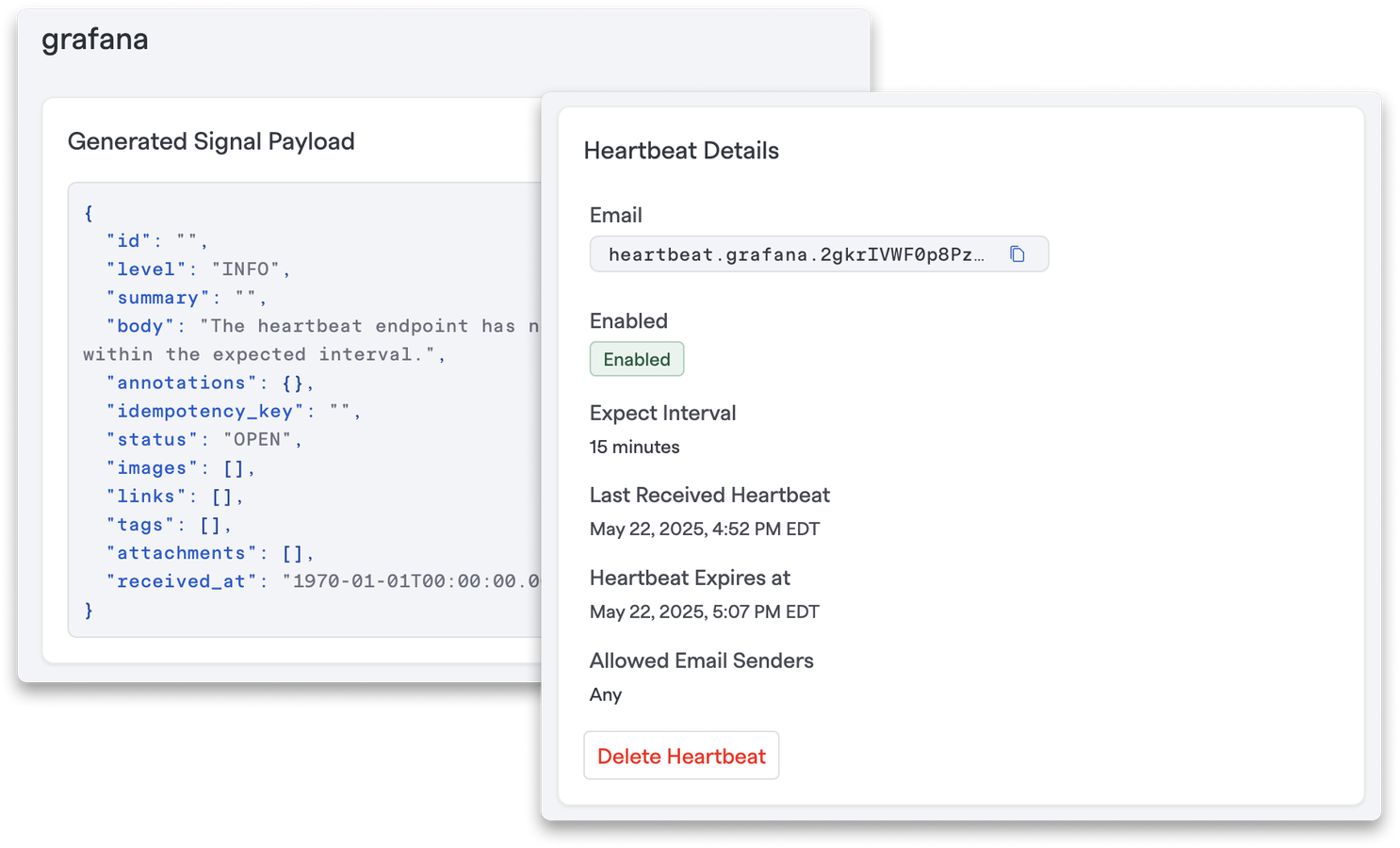
Signals includes Heartbeat Monitoring, a must-have for any critical system. FireHydrant expects periodic "heartbeat" events, and if they go missing, Signals automatically dispatches an alert.
This helps your team:
- Catch silent failures before they become fire drills
- Ensure scripts, tasks, and scheduled jobs are still running
- Sleep better at night, knowing you’ll be notified if anything falls quiet
Beyond Alerting: Full Lifecycle Incident Management#beyond-alerting-full-lifecycle-incident-management
Because FireHydrant includes incident management natively, your team doesn’t have to switch tools or lose context mid-crisis. Alerts and incidents stay connected, with timelines, roles, and communication channels already set up and ready to go.
Our all-in-one platform is built to guide teams through the entire incident lifecycle — plan, response improve — empowering teams to create structured, repeatable processes, respond faster and more collaboratively, and improve after every incident.
Plan: Prepare for the Unexpected#plan-prepare-for-the-unexpected
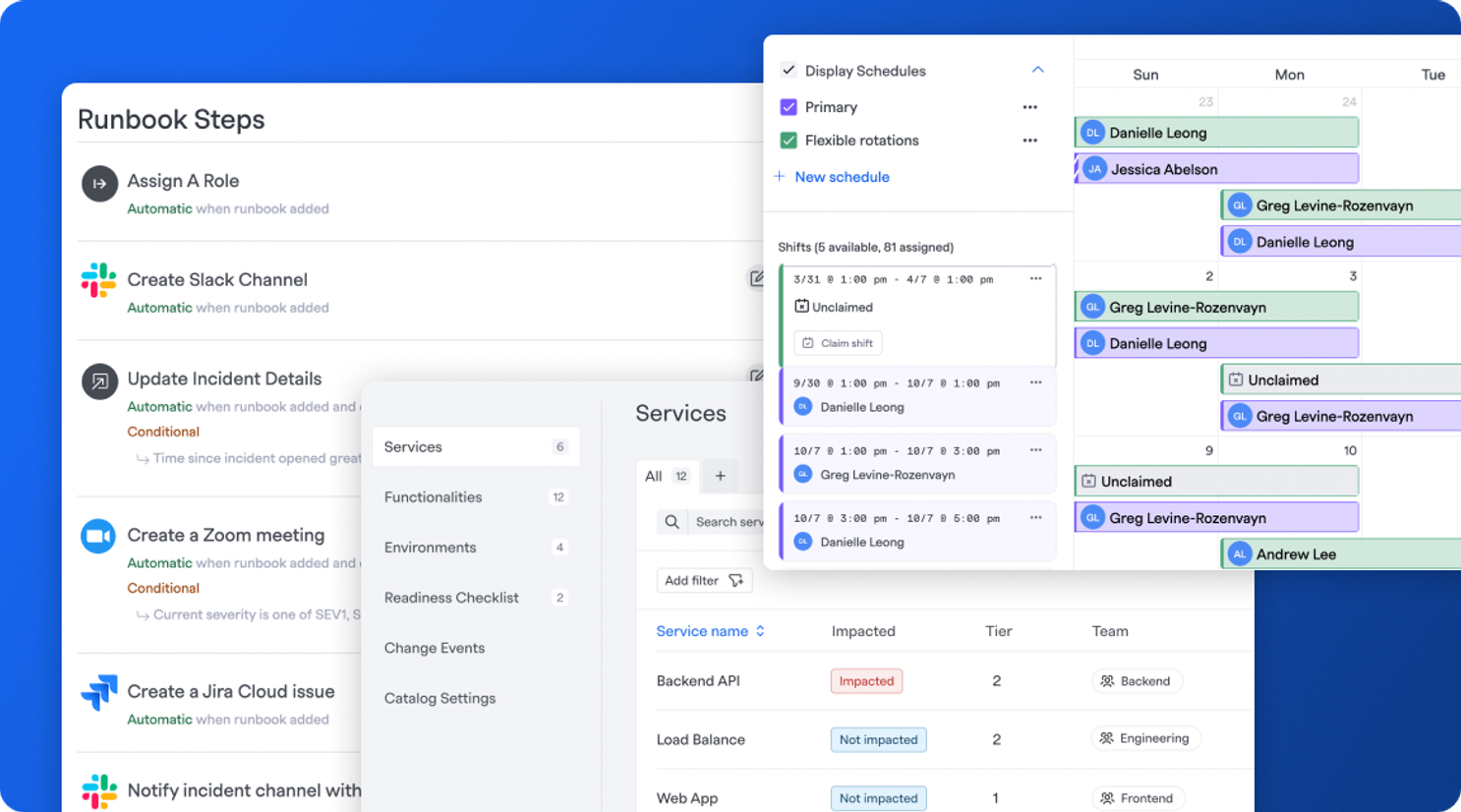
Before an incident, FireHydrant helps your team stay ready with:
- Modern, flexible on-call scheduling and alerting: As mentioned above, FireHydrant offers everything you love and expect from Opsgenie. Centralize alerts and cut through the noise, so only the right teams get notified. Create on-call schedules, automate escalations, and page, acknowledge, and handoff from Slack, Teams, mobile, WhatsApp, email, voice, and SMS. Learn more.
- Automated runbooks: Turn institutional knowledge into repeatable workflows that can be kick off automatically when incidents begin, based on criteria like severity or impacted service. Learn more.
- Built-in service catalog: Map ownership and dependencies clearly, so there's clear visibility into what’s what’s breaking and who owns it. Learn more.
Respond: Move Fast With Clear Direction#respond-move-fast-with-clear-direction
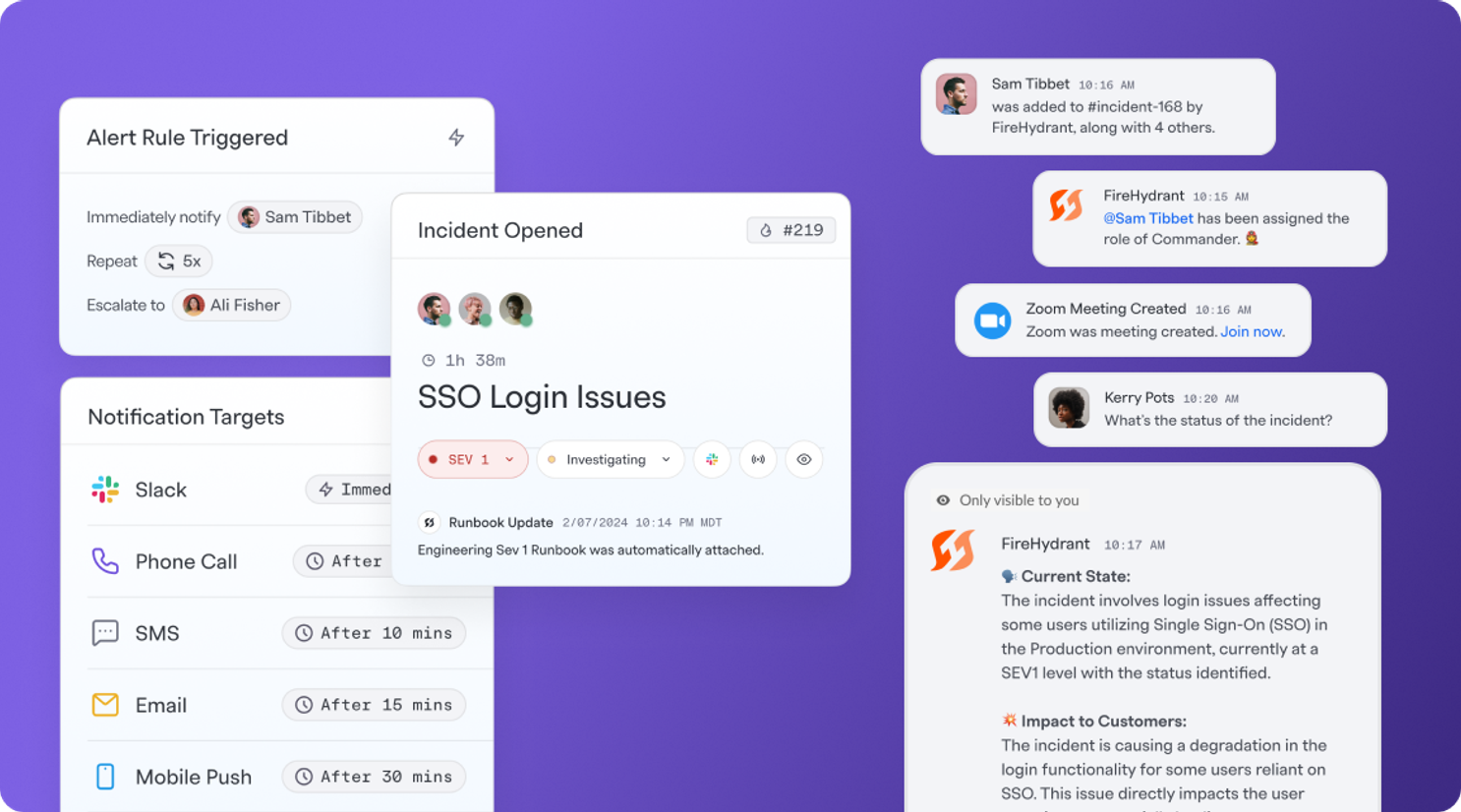
During an incident, FireHydrant cuts through the chaos with:
- Automated incident response: Instantly kick off workflows, assign roles, and launch communication channels without any manual effort.
- Seamless collaboration in Slack or Teams: Turn chat into your real-time response hub to coordinate in real time where your team already works.
- AI-enhanced response: Like an extra set of hands during incidents, our AI provides insights and captures every detail — AI summaries (tailored to different audiences), status page updates, and video meeting transcriptions. Learn more.
- Internal and external status pages: Keep stakeholders informed with real-time updates — no extra work required.
Improve: Turn Data Into Decisions#improve-turn-data-into-decisions
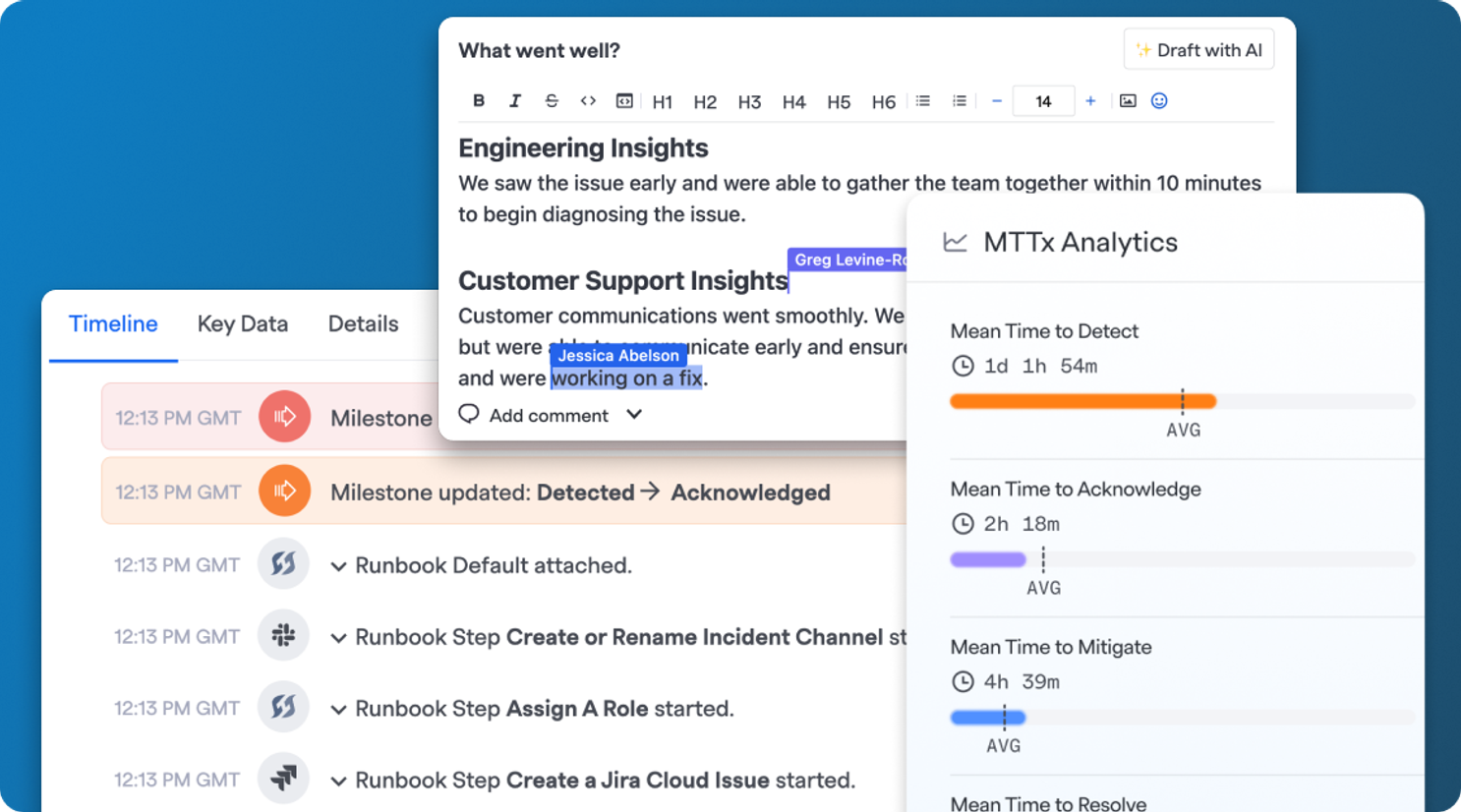
After the incident, we help you learn and improve with:
- Incident timelines: Like your black box recorder, FireHydrant automatically captures every step of the incident and turns it into a clean, comprehensive timeline.
- AI-enriched retrospectives: Generate clear, actionable insights in seconds — not hours. Create polished reports for the C-Suite, exportable to Google Docs, Confluence, or PDF. Learn more.
- Incident analytics and trends: Track metrics like MTTR and spot recurring patterns to guide continuous improvement. Learn more.
- Intelligent follow-ups: Ensure nothing slips through the cracks, with tasks synced directly to Jira or ServiceNow.
Instead of stitching together alerting and incident response across tools, FireHydrant gives you one seamless experience — designed for speed, clarity, and scale.
We Turned Switching Costs Into a Migration Feature#we-turned-switching-costs-into-a-migration-feature
We know switching alerting tools isn’t a small decision. That’s why we’ve built a smooth, structured migration process that makes moving from Opsgenie to FireHydrant as seamless as possible — with better workflows as the end result.
When you migrate, you get:
- Automated migration tools that export your Opsgenie config into Terraform-ready files
- Hands-on support from our Solutions Engineering team every step of the way
- Customized onboarding based on your current setup, future goals, and what you want to change
- Training for your whole team — from alert routing to on-call scheduling to real-world gamedays
- Dedicated Customer Success and shared Slack channels for fast answers and continuous guidance
Whether you want to mirror your current setup or start fresh with a more modern approach, we meet you where you are. We’ll work with you to review your Opsgenie configuration, map your observability integrations, and ensure you come out the other side with a system that’s even better than what you had before.
By the end of your migration, you’ll have:
- Your schedules, escalation policies, and alert routing live in FireHydrant
- Your integrations reconnected and tested
- A trained, confident team
- Infrastructure as code (if you want it)
- And a customer success partner that stays with you long after go-live
Your New Home After Opsgenie Shuts Down: Familiar, But Built to Take You Further#your-new-home-after-opsgenie-shuts-down-familiar-but-built-to-take-you-further
As Opsgenie shuts down, you don’t have to sacrifice reliability, simplicity, or control. Switching to FireHydrant won’t feel like starting over. You’ll recognize the principles and patterns you’ve relied on — but now with more power, more flexibility, and a faster path to resolution.
And unlike legacy tools that come with bloated pricing and bolt-on complexity, FireHydrant delivers everything your team needs, at a price that scales with you.
Get ahead of the Opsgenie sunset: Request a demo and see how FireHydrant can be your new home for alerting and incident response.