Let’s talk bugs versus incidents
In this post, we’ll dig into the difference between a bug and an incident, why alignment on how they are defined matters, and how to ensure you’re still learning from the issue, even if it’s “just a bug.”

Like so much when it comes to incident management, the definitions of a bug and an incident vary by organization — and when you’re not aligned, sometimes the definitions vary even within an organization. For example, I’ve seen incidents declared because a bug was introduced internally or because there’s an issue with an external dependency, even though the customer impact was minimal.
Having a shared language around what constitutes a bug versus an incident, and a process to deal with both, helps your team more appropriately and efficiently label and then respond to either situation.
In this post, we’ll dig into the difference between a bug and an incident, why alignment on how they are defined matters, and how to ensure you’re still learning from the issue — even if it’s “just a bug.”
Why do we need to define software bugs and incidents?#why-do-we-need-to-define-software-bugs-and-incidents
When we talk about bugs or incidents, what we’re really talking about is any interruption in how your product or technology is expected to behave. How we evaluate the seriousness of those issues informs the way we respond to them: do we drop everything else and rally the troops immediately or do we add a fix to the next sprint? So really, defining a bug vs. an incident is less about the type of issue that arises, and more about the response it requires.
Consider this example: A customer flags an abnormality with your app. In most situations, you’d likely launch an investigation and lean on your observability tools and SLI/SLOs. You’d determine if it was a customer-specific event or if there were other issues that could point to a more urgent need to get to mitigation.
However, if the customer experiencing the issue has a high impact on your business or has very specific SLA, your response might change. What’s considered a bug might jump in urgency to a SEV3 incident, for example. Ultimately it comes down to customer impact — it’s more than just “what’s a bug?” and “what’s an incident?” You need to also account for who and what will be impacted as a result.
Get aligned on software bugs vs incidents#get-aligned-on-software-bugs-vs-incidents
To get clear on how your organization defines a bug vs. an incident, we suggest forming a working group between customer-facing, product, and engineering teams to create those definitions. These two teams can give you context for both customer impact and pain, as well as system functionality — both of which are needed to define what constitutes a bug versus an incident.
As a starting point for those definitions, one way to think about bugs and incidents is in the context of a psychological state for the responding team. For example:
- A bug has a lower sense of urgency; teams often have time and space for investigating and discovering because customer impact is minimal.
- An incident has a higher sense of urgency; teams are on-deck to fix the issue as quickly as possible, usually because customer impact is high.
When your own definitions are clear, encourage your customer-facing and engineering teams to work together to set expectations on the response efforts for bugs and incidents among responding teams and stakeholders. And be sure to identify when and what type of extenuating circumstances may shift the severity and, therefore, the response.
If you haven’t already created your own severity level definitions, this is a good time to do so. Severity levels help you determine the appropriate response to an incident (or a bug) based on the impact of the issue.
What if you treated bugs like low-sev incidents?#what-if-you-treated-bugs-like-low-sev-incidents
As we’ve discussed, a bug is often low pressure. The stakes are different because you’re investigating and no external communications are going out. Your team has room and time to dedicate to the investigation to determine what’s going on because it’s not causing a wide, customer-impacting issue.
Now imagine if this process to investigate was normalized as an incident. By creating an incident type specific to investigations — like we did at FireHydrant — you could still follow a lightweight process where you trigger the creation of Slack channels for discussion, provide a location to document observations, and maybe even inspire your team to pull in another set of eyes to look at the bug together. Maybe you just don’t send out any external communications the way you would with higher-severity incidents.
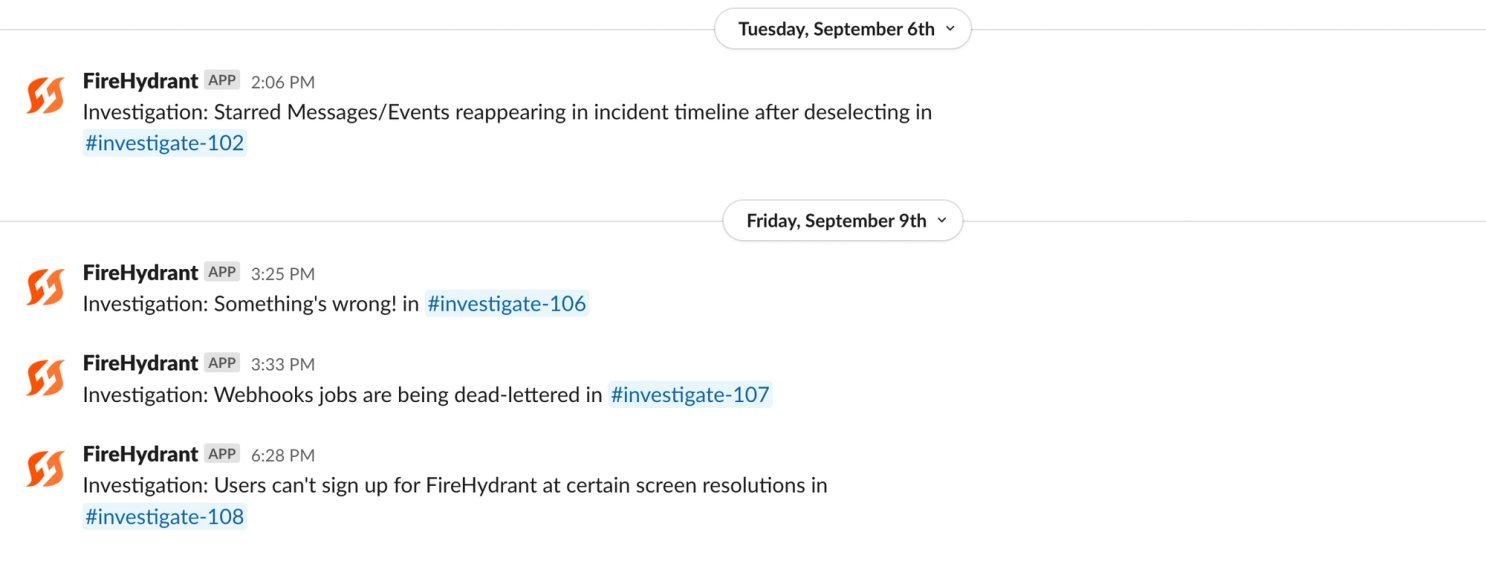
Normalizing the incident response process for an investigation enables your team to build their incident response muscle. Practicing the incident response process you have in place in a low stress situation ensures your team is better prepared to navigate the needs associated with a higher severity incident when one arises.
Find what fits for you#find-what-fits-for-you
Bugs and incidents, like so much in incident management, are defined by the context of your organization, your product, and your goals. By aligning on definitions and creating an investigation incident type for bugs, you not only right-size the response, you also gain the ability to document, analyze, and learn from the bugs. And that ultimately leads to improvements in both your systems and processes.