Incident severity: why you need it and how to ensure it’s set
Incident severity helps responders and stakeholders easily understand the impact of the incident, and set expectations for the level of response effort. Both of these help you fix the problem faster ... but first, you have to ensure severity is being set.

Defined severity levels quickly get responders and stakeholders on the same page on the impact of the incident, and they set expectations for the level of response effort — both of which help you fix the problem faster.
But sometimes, for whatever reason, a severity level just doesn’t get set. Maybe there’s confusion around what severity level to use. Or maybe you have a low barrier to declaration and your responders just need a little nudge. In this blog post, we’ll talk about why severity is important and help you ensure it gets set.
Why does severity matter?#why-does-severity-matter
When used correctly, severity levels help set expectations for response efforts and prioritization during the incident, and they also help you uncover patterns over time. The important thing to stress is that this isn’t just for “checking a box.” After talking to hundreds of people over the years about how they manage incidents, I’ve recognized a handful of advantages to ensuring severity levels are set on incidents.
Prioritization: By assigning a severity level, you can prioritize resources and efforts based on the severity's impact on business operations. High-severity incidents typically require immediate attention and may involve critical functionality, whereas lower-severity incidents may have minimal impact and can be addressed at a later time.
Resource allocation: Higher-severity incidents usually demand a more significant allocation of resources, such as experienced engineers, technical experts, or even involving cross-functional teams. Lower-severity incidents may require fewer resources, allowing teams to focus on higher-priority issues.
The ultimate measure of an incident is its impact on customers. Generally speaking, the higher the impact on your customer, the higher the severity of the incident.
Communication and escalation: Severity levels provide a common language for communication within the organization and help establish clear expectations. When stakeholders understand the severity level, they can align their response and escalation processes accordingly.
SLA compliance: The ultimate measure of an incident is its impact on customers. Generally speaking, the higher the impact on your customer, the higher the severity of the incident. When defining severity levels, it's paramount to understand how you define uptime for your customers and consider any contractual obligations, like customer-facing SLAs. Breaching an SLA often has punitive impacts on your organization and, more importantly, will lead to a poor customer experience.
SLAs help you set a danger zone: the more your product gets to a state approaching an SLA breach, the higher the severity of an incident. Without SLAs, think about worst-case scenarios for your customers. For example, your scale of impact might go from not being able to use your product to missing website elements that don't impact the experience.
Continuous improvement: Severity levels contribute to post-incident analysis and continuous improvement efforts. By categorizing incidents based on severity, you can analyze patterns and identify areas for improvement. This data-driven approach helps identify recurring high-severity incidents, determine root causes, and implement preventive measures to reduce the impact of future outages.
How do you determine severity?#how-do-you-determine-severity
Severity definitions should be in plain language. You want them understood and used by every member of an organization, not only engineering. Without easily understood definitions, severity is applied inconsistently across incidents — potentially confusing the response — or not set at all.
There are varying ways to define severities — for example, some teams include a SEV0 to indicate an absolute catastrophe. The method we use at FireHydrant is to define severity levels from SEV1 to SEV3.
SEV1: No customer can use most, or all, of a product or service. Most pages in our product are not loading or displaying an error message. Data corruption or loss has occurred or will occur. Loss of revenue is happening or imminent.
SEV2: Primary product functionality is severely impacted and unusable. Customers are unable to utilize a common feature to its fullest ability. Data may not be displayed as expected but not lost. There is no workaround for customers.
SEV3: Some customers (not all) receive intermittent errors on product pages or cannot use the product in obscure ways. The product may be loading slowly or partially (missing images), and there is a workaround that customers can use.
One thing to remember when standardizing severity level definitions is you might classify the same incident differently if it happens at 2 a.m. when your customers aren’t active, as opposed to at 2 p.m. during peak hours. The all-hands-on-deck response effort you might employ would be overkill at 2 a.m.
An interesting thing about severity levels is that you can grow them with your program. Over time, you’ll look back in retros and decide that really that incident you called a SEV2 at the time could’ve been downgraded to a SEV3. The more you use them, the more you learn.
How do you ensure severity is set?#how-do-you-ensure-severity-is-set
Even if everybody is on the same page regarding the importance of severity, it may still just not get set. Sometimes the responder might just forget. Or, if you’re like us, you want everyone to feel comfortable declaring an incident, so you don’t actually require a severity level to be assigned upon declaration.
The challenge in this approach though, is finding the right balance so folks feel extremely comfortable kicking off incidents initially without having a severity set, but then go back and set a severity later if needed. You can do this using FireHydrant by setting a reminder in the incident channel when no severity is set after a certain time window has passed.
To set up your own reminder in FireHydrant, follow these steps:
First, either choose an existing runbook to edit, or create a new runbook in FireHydrant.
Now, add a step in the runbook to “Notify incident channel with a custom message”
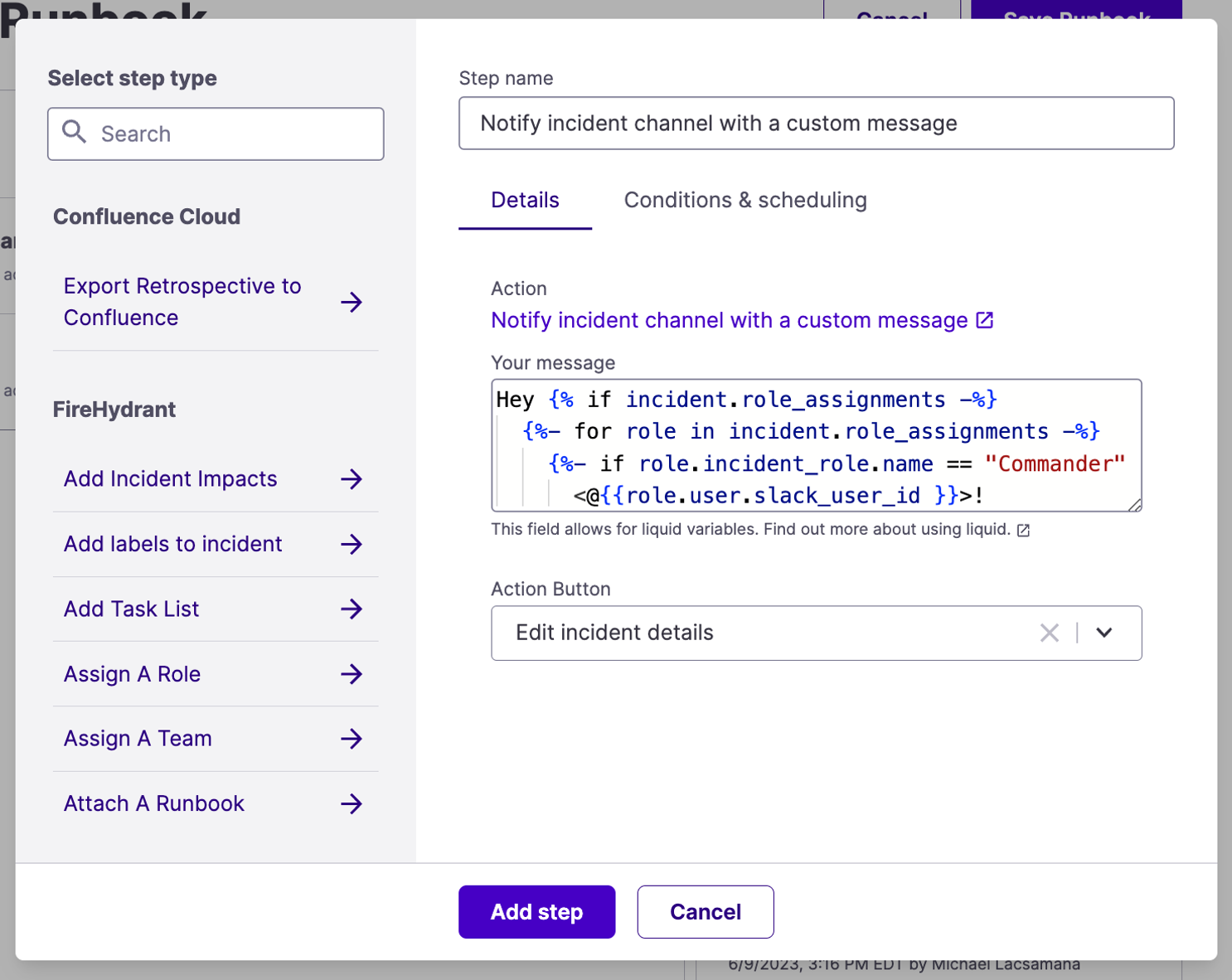
Within “Your Message”, copy and paste the following:
Hey {% if incident.role_assignments -%}
{%- for role in incident.role_assignments -%}
{%- if role.incident_role.name == "Commander" -%}
<@{{role.user.slack_user_id }}>!
{%- endif -%}
{%- endfor -%}
{%- endif %}
It's been a couple minutes since the incident has been open. Please set a severity.Next, navigate to “Conditions & Scheduling”. Under “Rules”, select “Time since incident opened greater than 2m” AND “Current severity is UNSET”. This will ensure this message will only post to the incident channel within 2 minutes (or whatever timeframe you decide on) if and only if no severity is set for the given incident.
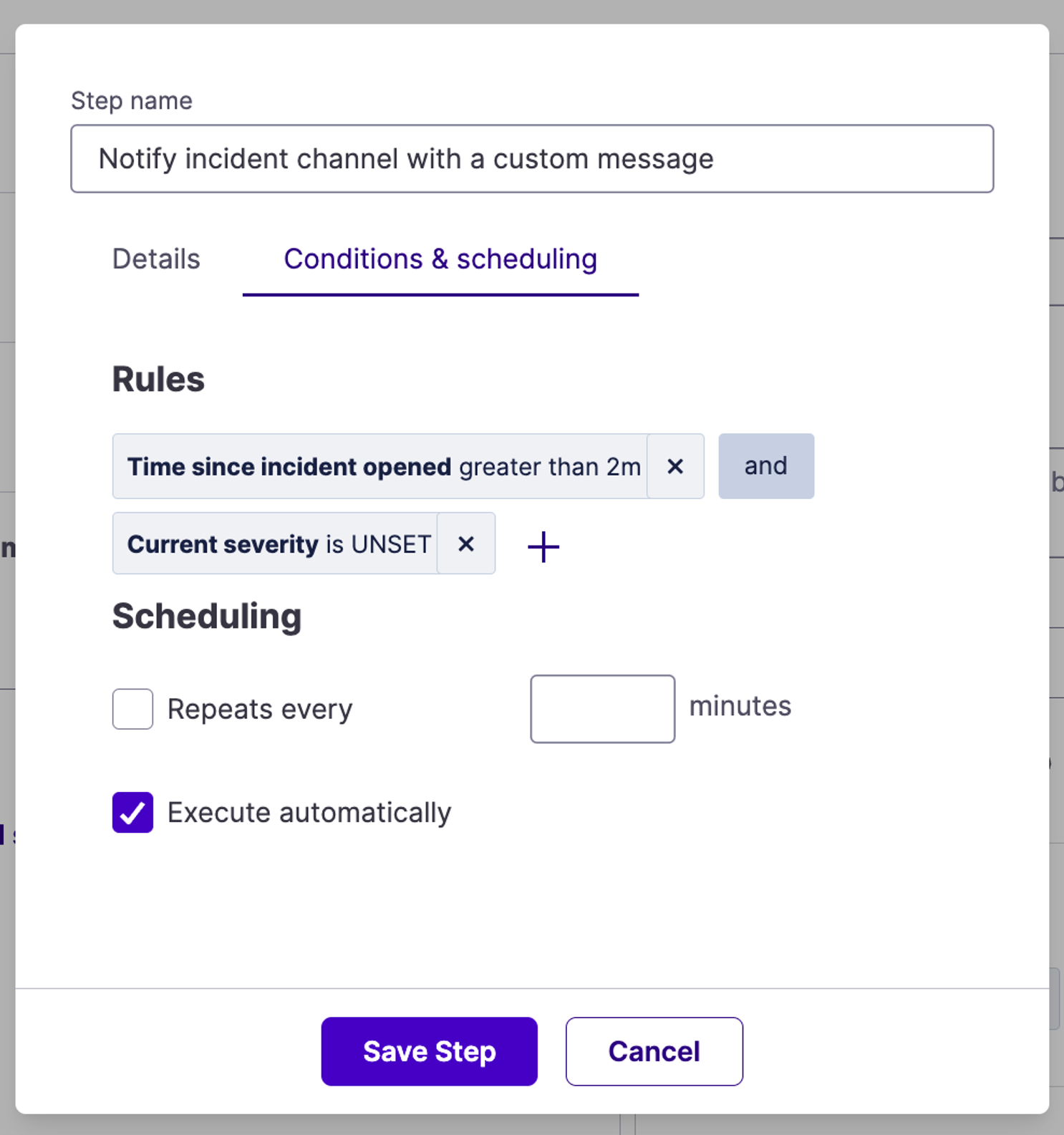
And voila! Your reminder is set.
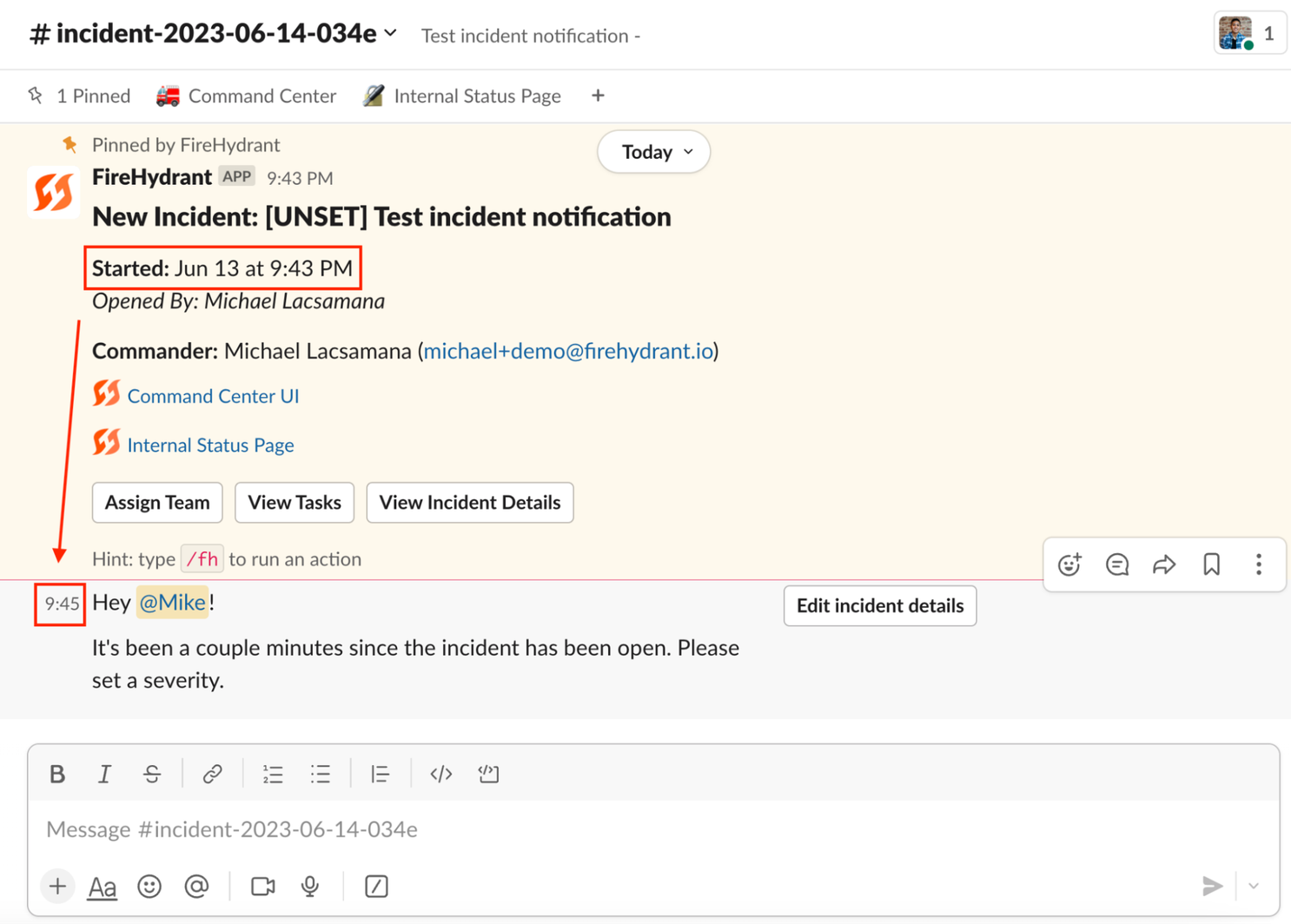
Note: In the example above, we are assuming that a Slack channel has been created and at least one role has been assigned to a user.
Give it a go#give-it-a-go
Hit me up on LinkedIn if you try this out. I’d love to hear how it goes. And if you’re not yet a FireHydrant customer, see what we can do for you.