What is FireHydrant?

What is FireHydrant?
FireHydrant is a full-cycle incident management platform that makes your incidents less painful. From automating toil to efficiently assembling the right teams, standardizing communications, facilitating better retrospectives, and gathering metrics, FireHydrant helps organizations improve their reliability and resilience.
Why use FireHydrant?
With FireHydrant, you can:
- Automate manual tasks such as creating incident Slack channels, Jira tickets, meeting bridges, and more
- Integrate with alerting and monitoring integrations to automatically create incidents from alerts
- Standardize processes and tailor them for different situations, product areas, and teams, among other criteria
- Keep track of your apps, services, environments, and their relationships, and automatically pull in responders based on impacted product area
- Maintain traceability of incident management data, communications, and action items
- Learn valuable lessons from your incidents, and use that knowledge to improve your infrastructure and processes
Key Components
Incidents
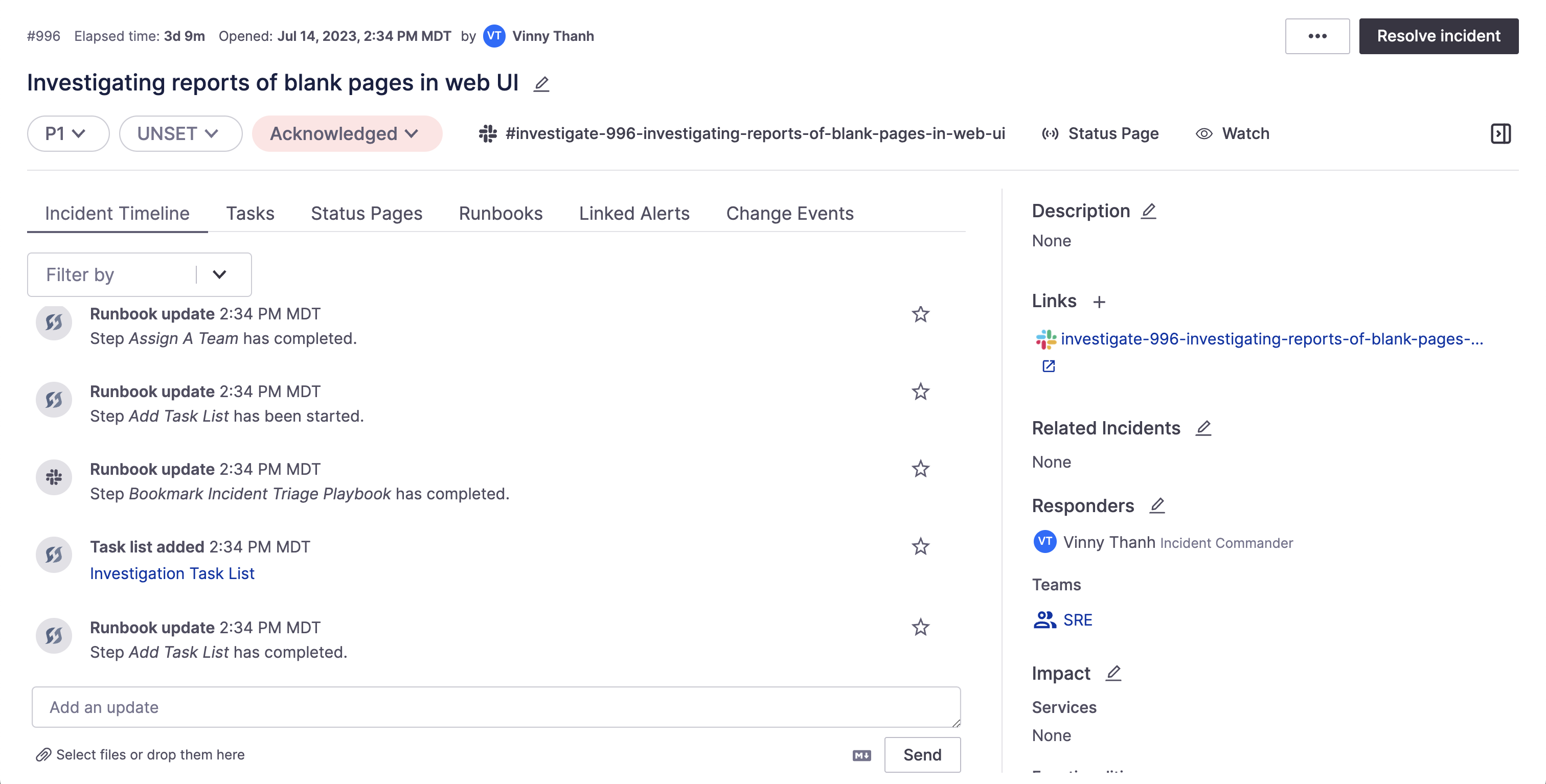
The "Command Center", or incident home
Incidents are the bread and butter of FireHydrant. FireHydrant's incidents help your team stay organized and respond to situations efficiently while alleviating the need for "scribe" or "note-taking" roles by tracking incident events automatically.
Incidents can be created through the FireHydrant UI, from Slack, through our API, or through integrations. Combined with the numerous other platform offerings below, from automation, to tracking your catalog, to managing tasks and conducting informed retrospectives, FireHydrant is here to help you Automate, Respond, Learn, and Improve.
Runbooks
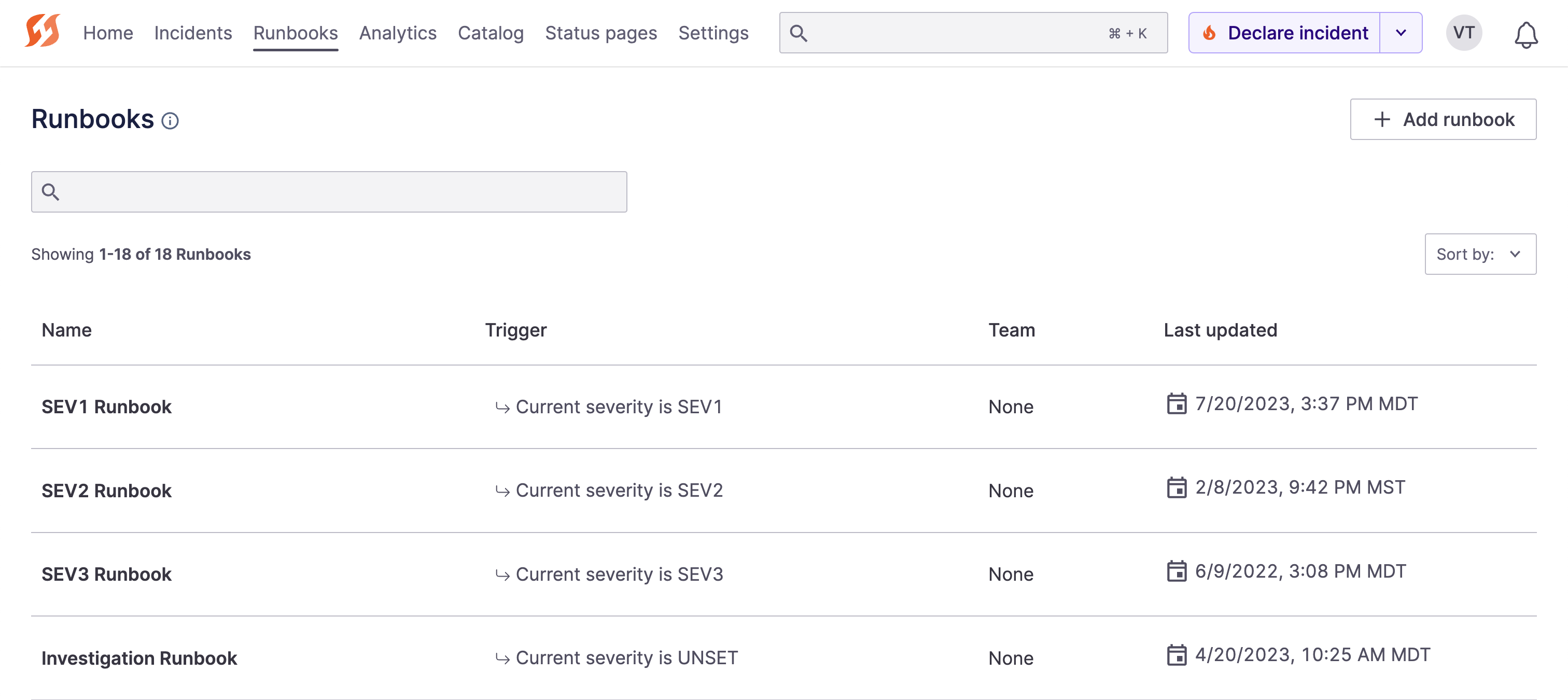
Runbook Automation for Different Triggers
Runbooks are what make FireHydrant unique and powerful. Say goodbye to wikis and endless static playbooks; FireHydrant enables you to automate your processes, including step execution with conditional logic.
Runbooks can be tailored to different situations and severities, by teams, by product/service, and more, and they can even be layered together. With FireHydrant Runbooks, your team can stay focused on fighting fires instead of reading documentation and manually toiling.
See our Runbooks Basics for more information.
Service Catalog

Service entries in the Catalog
FireHydrant hosts a Catalog for your infrastructure to help your team stay organized. With the Catalog, you can track which properties are impacted by an incident, any dependencies between items, and who owns these properties + should be involved in an incident, among other things.
Combined with Alerting Providers and Slack, you can automatically pull in the right people and teams for the right parts of your system having issues in only a few seconds.
You can manage your FireHydrant Catalog from Web, API, or Terraform, or you can import these services from various providers. See our Service Catalog Basics for more information.
Role & Task Management

Notification received in Slack when assigned to roles and tasks
FireHydrant has complete task and role management built into the platform. Rather than context-switching to external wikis or playbooks, you can pre-define important to-do items within FireHydrant and track task completion as incident timeline items.
In addition, you can customize incident roles for your organization's needs, allowing every responder to know exactly what is expected of them when they're pulled into an incident.
Retrospectives
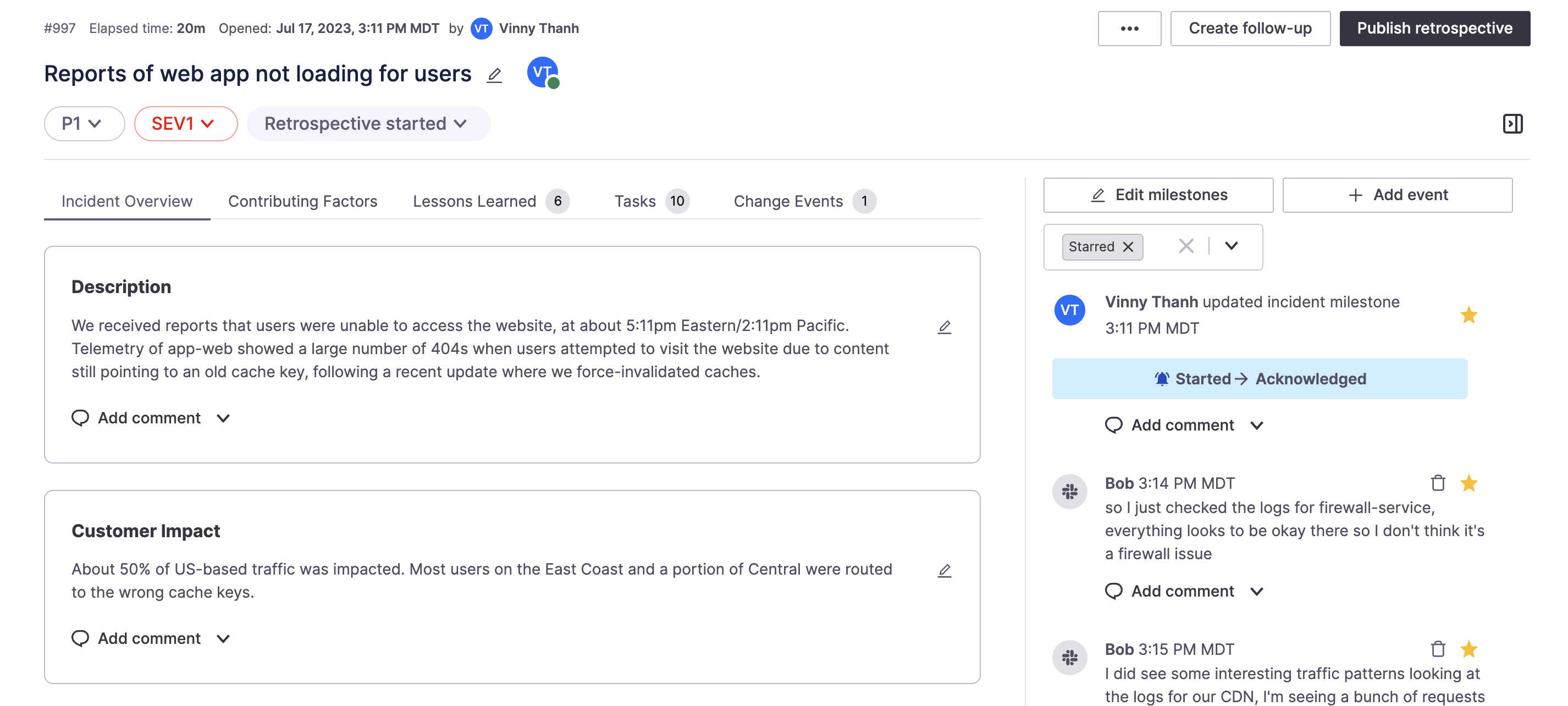
Incident Retrospectives in FireHydrant
Once an incident is resolved, FireHydrant helps teams facilitate better incident reviews with built-in Retrospectives. Retrospectives gather and contextualize information and timeline events from all throughout the incident so your team has a clear view of what happened and why it happened, and can have conversations about how to prevent future occurrences.
More importantly, teams can list out Contributing Factors, customize questions/answers in Lessons Learned, and create follow-up action items in linked external ticketing tools to plan work in future sprints.
Learn more about FireHydrant's Retrospectives here
Integrations
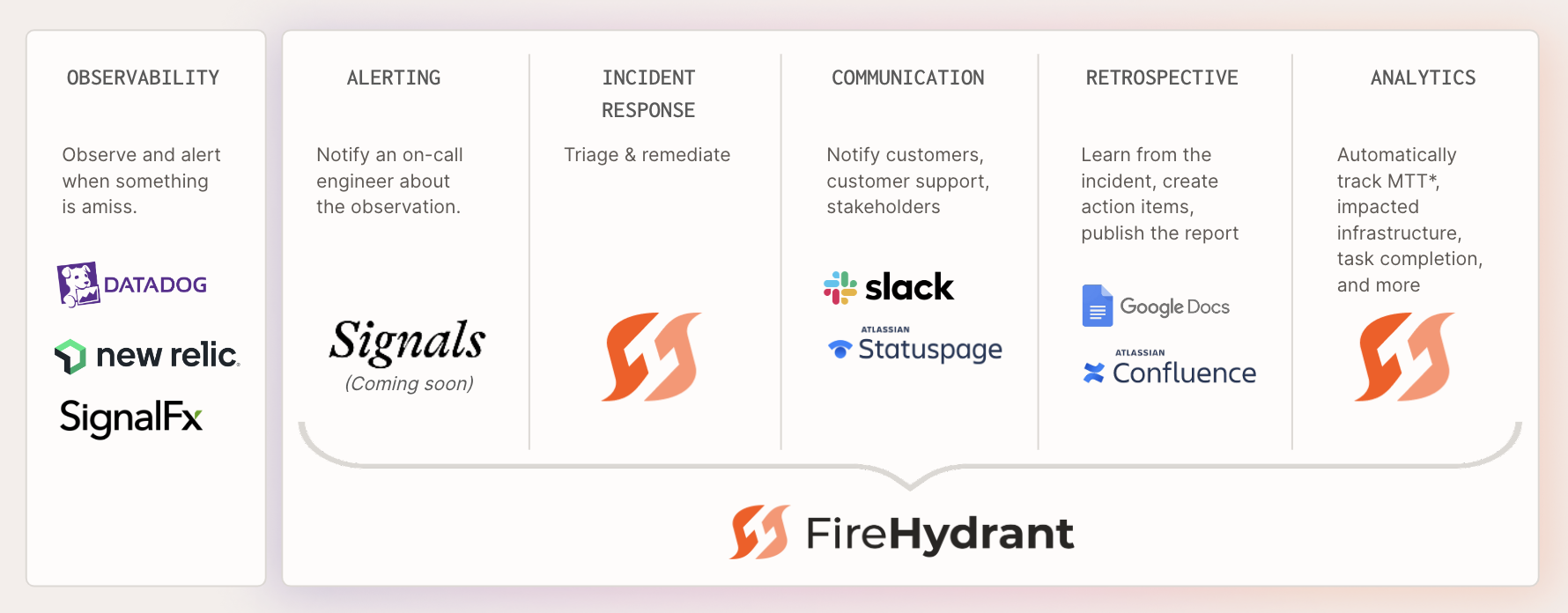
FireHydrant Full-Cycle Incident Management
FireHydrant supports a growing list of integrations. From chat providers like Slack, to alerting providers like PagerDuty and Opsgenie, and others like Zoom, Google Docs, Jira, Zendesk, Kubernetes, Okta, etc., FireHydrant can meet your team where it currently works.
For a complete overview, see Integrations Overview.
Other features
Incident Types
You can fill in information for your incidents ad-hoc, or you can pre-define [ for your operators to easily declare. This is useful to remove the cognitive load for your teams to declare specific types of situations, pulling in the right responders and resources every time.
Team Management
FireHydrant's Teams allow you to quickly assign a group of people to an incident from Slack or the UI. They're also a great way to see which groups own the services in your application stack.
Severities
On top of customizing your severities, FireHydrant reduces the stress of figuring out how severe an incident is by enabling you to configure a Severity Matrix. If certain functionality is down, automatically assign severities. Now, your incident response team can create incidents and be confident that the correct severity is applied.
Change events ingestion
Many incidents are caused by deploys or configuration changes. With FireHydrant, you can easily view your deploy events associated with different pieces of infrastructure so you can more quickly track the cause of your incidents. FireHydrant supports ingesting Change Events via the API as well as through our Kubernetes and AWS CloudTrail integrations.
Status pages
FireHydrant offers two out-of-box status page features: incident-specific status pages and system-wide, global status pages. Incident-specific status pages are private, temporary status pages that expire after 48 hours of your incident being resolved. Global status pages can be public or private, and they are meant to show the status of your platform or application's individual components at any given time.
FireHydrant also offers an integration with Atlassian Statuspage
Analytics
FireHydrant gives you a quick view of your historical incidents and infrastructure health so you know where to focus your efforts and how you can improve your incident response process moving forward. Analytics include breakdowns of incidents by system components, response metrics like remediation time, and much more.
Next Steps
With all of the above stated, check out the following resources:
- Check out FireHydrant's Product Demo for a glimpse of FireHydrant in action
- See the Quickstart Guides to dive right into FireHydrant
- Browse the overview of integrations that FireHydrant supports
- Browse our comprehensive guides that fully explain all of FireHydrant's capabilities
Updated about 1 month ago